> **Supported devices.** This essay includes interactive demos that are not optimized
> for small screens and touch. To fully explore the demos, you will need a desktop computer or a laptop.
> The page has been tested with recent versions of Firefox and Chrome.
**_1._ Introduction:** From programs to programming
----------------------------------------------
A typical theorem of a theoretical programming language research paper starts with a phrase
_given an expression $e$_. This phrase hides all the interesting interactions that occur during
program construction between the programmer and their editor and tools. Most modern code editors
make recommendations through auto-complete, provide quick feedback through background code
checking and offer tools for refactoring programs. Programmers using test-driven development (TDD)
switch between editing their tests, running a test runner and adding functionality. Last but not
least, data analysts write code in notebook systems that let them run it immediately, see the
results and refine their code accordingly.
Much work has been done on making programming more live and interactive ([Tanimoto, 2013](#refs)).
Early programming environments for dynamic languages like LISP and Smalltalk ([Sandweall, 1978](#refs),
[Goldberg and Robson, 1983](#refs)) offered ways of modifying programs without restarting them; visual
programming languages further developed the live programming paradigm ([Burnett et al., 1998](#refs)),
Bret Victor illustrated the potential of live programming ([Victor, 2012a](#refs), [Victor, 2012b](#refs))
and many authors explored those further in the context of user interfaces ([McDirmid, 2007](#refs)),
musical live coding performances ([Aaron and Blackwell, 2013](#refs)), app development
([Schiller et al., 2014](#refs)) or data science ([DeLine et al., 2015](#refs)).
In contrast to the above, this essay does not (yet) present a new and better live programming
environment. We take one more step back and aim to replace the formulation _given an expression $e$_
with a modern equivalent that reflects the interactive nature of programming. We represent a program
as a _list of interactions_ through which it was constructed. We explore what kinds of tools this
approach lets us build. To make our case more apparent, our example focuses on the kind of
programming done by data analysts who use notebook environments to programmatically explore
data using languages such as Python. However, thinking of programs as lists of interactions
could inspire the design of other modern interactive programming tools, most likely with different
but equally interesting consequences.
**_2._ Background:** How data analysts work
--------------------------------------
Programmatic data analysis makes for a perfect sample domain for research on interactive programming
tools. Most data analysts already use notebook systems such as Jupyter ([Kluyver, 2016](#refs)),
which blur the distinction between development and execution. Notebooks implement the idea of
literate programming and make it possible to combine text, equations and code with results of
running the code, such as tables or visualizations.
Data analysts typically write small snippets of code, structured as _cells_ or code
blocks in a notebook. They run such snippets interactively, modifying the live state of
the notebook. They then inspect the results and refine their code accordingly. They might
refactor some code into a reusable function, but the overall structure of code they write
remains very simple.
The idea that programming is an interactive process is very easy to illustrate in the
context of programmatic data analysis. The following demo shows a basic example of using
Python with the pandas library ([McKinney, 2011](#refs)) to explore data on air traffic
accidents in Europe from [Eurostat](https://ec.europa.eu/eurostat/statistics-explained/index.php/Air_safety_statistics_in_the_EU#Overview_of_fatalities_in_air_transport_in_the_EU).
Our input is consists of one CSV file per year with rows capturing individual accidents
and we are interested in major accidents that resulted in multiple deaths.
> **How does it work?** The following section uses the _scrollytelling_ technique
> to let you go through individual steps of the demo at your own pace. Scroll down to move
> forward and scroll up if you want to return to an earlier step.
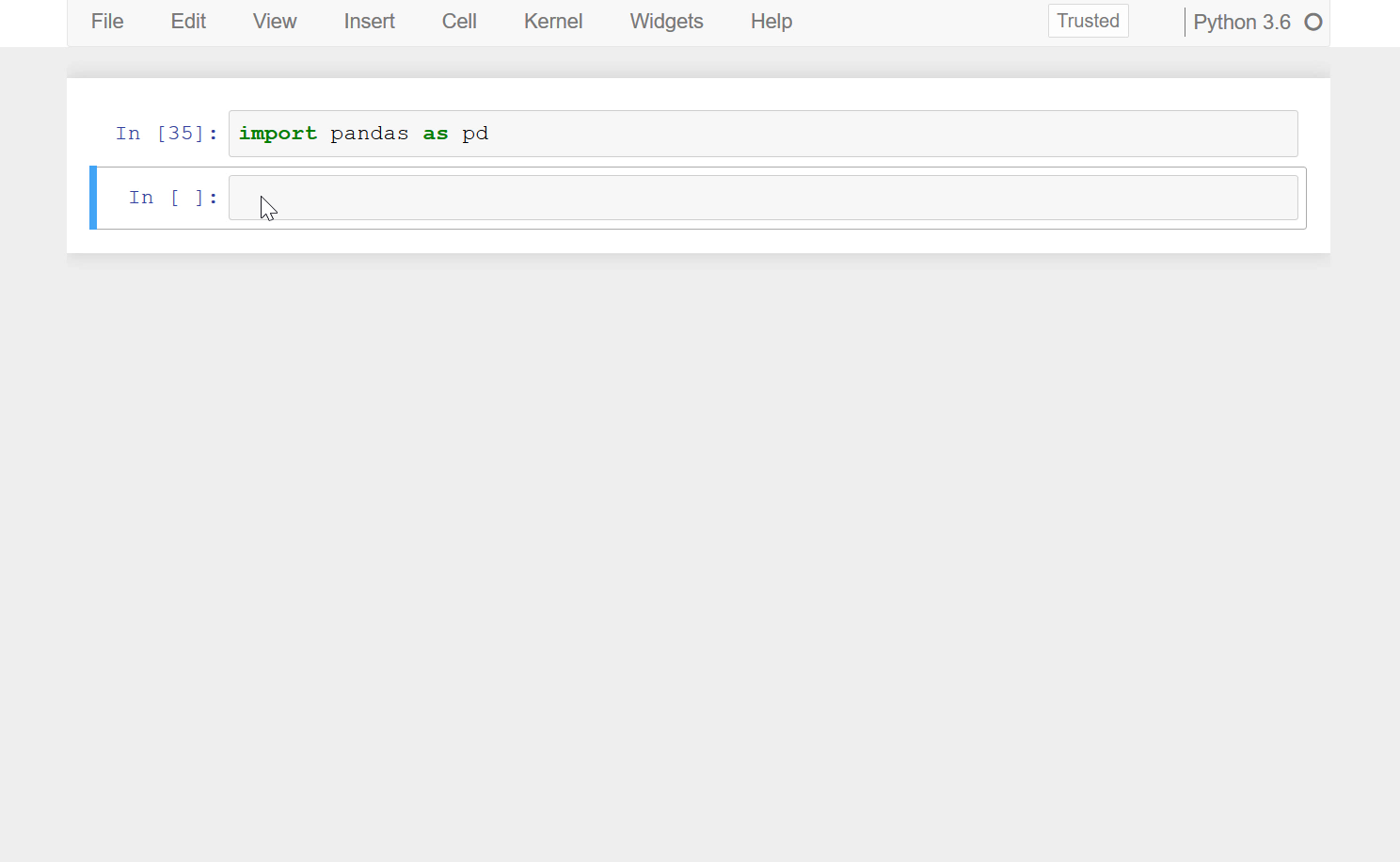
There are a number of general points that are illustrated by the above demonstration:
1. Running code is an interaction that occurs during the process of writing a program.
When analysing data, we run code to understand our inputs and check that our data processing works
as expected. When building software systems, running code is less evident, but similarly
important -- developers regularly run code when using test-driven development or when evolving
scripts written using the REPL to programs.
2. Once we package code as a function, it becomes harder to debug and test. When writing code,
we put loading in one cell so that Jupyter displays the result in a table. Once we
package code as a function, it becomes a black-box. When we change it, we cannot see
intermediate results, which makes it harder to discover and fix bugs.
3. The names of members on the object that represents a data frame depend on the contents of
a file that we load. For example, when we write `raw[raw.value > 10]`, we know that
`value` is a column of the data frame only because we looked at the output of the
`pd.read_csv` file that we executed previously.
4. Most of our interactions are text-based. When defining a function, we copy the text from
two cells we created earlier. We also often have to come up with the name to type, for example
when invoking operations such as `head`, `query` or when writing the condition passed to `query`.
Auto-complete can help with some of those, but not always.
There are programming environments for which the above points do not hold. For example, Kepler
([Ludäscher 2006](#refs)) is a non-textual scientific data analysis system, while type providers
([Petricek, 2016](#refs)) import external data into a programming language. However, the above
demo and observations are typical for present day workflow of a data analyst who uses programming
tools.
**_3._ Histogram**: Programs as lists of interactions
------------------------------------------------
The key idea of this essay is that we should represent programs as lists of interactions.
The essay includes a prototype implementation that lets us explore the consequences of using such
representation for a programming task like the one presented in the above demo. We call our
prototype environment _Histogram_ (a portmanteau of _history_ and _programming_ which has nothing
to do with data visualization). We start with a short demo of Histogram and then discuss how
exactly Histogram works behind the scenes.
### _3.1_ Interacting with the Histogram environment
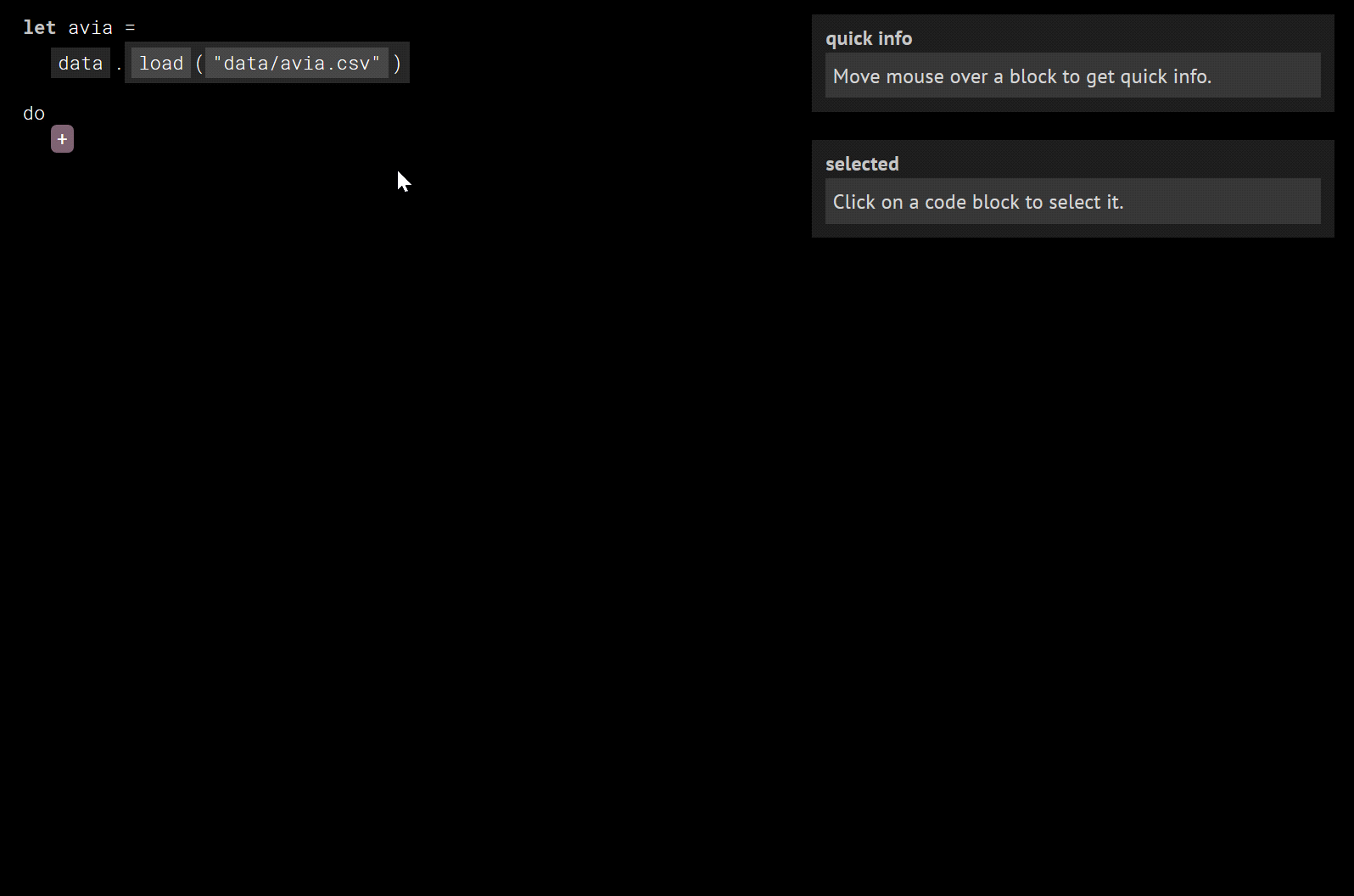
The following demo uses Histogram to load a file `avia.csv`, which contains data on air traffic
accidents in Europe for all years between 1990 and 2017. We find a row that corresponds to accidents
that occured in France and involved planes registered in Germany and then obtain the number of people
killed in the [Germanwings Fligth 9525 crash](https://en.wikipedia.org/wiki/Germanwings_Flight_9525).
> **How does it work?** The following section again uses scrollytelling, but it is also interactive.
> You can just scroll down to replay the demo, but you can also stop at any point and interact
> with the system on your own. If you do that, the auto-play will stop until you reset it. To
> do this, click the paperclip icon in the upper right corner.
> **Try it yourself.**
If you want to explore the environment on your own, try loading a data file
`data/rail.csv` which contains similar data on rail accidents. You can compare the
number of rail passengers killed in France and Germany by looking at two rows at
indices 3025 and 3018, respectively.
The demo shows a number of important points about the Histogram programming environment.
First, the program is displayed in a way that looks much like textual source code, but the program
is not represented as text and you cannot edit Histogram programs as text. This view is just
one way of displaying Histogram programs and we will see an alternative view later.
Second, much of programming is done by choosing options from auto-completion lists. Histogram follows a
design principle that prefers _choosing_ over _composing_, because making a choice is easier than
coming up with expressions without guidance. We follow this principle even when supplying
arguments to operations such as `load` and `at`, although one can imagine a variety of
usability improvements.
Finally, the demo shows Histogram in a simple developer environment with buttons, drop-down menus and
textboxes and it replays the interactions with the user interface. Histogram represents programs
as lists of interactions, but the user interface elements are not a part of the _language
specification_. The next section clarifies what counts as an _interaction_ in Histogram.
### _3.2_ Representing programs as lists of interactions
The representation of programs that we use in our prototype is perhaps best explained through a
small formal definition. Readers not familiar with programming language theory notation can see
this as an [algebraic data type](https://en.wikipedia.org/wiki/Algebraic_data_type) (or a
discriminated union) as known from languages like Haskell or F#. Note that we do not use the definition
for proving any properties in this essay, but we suggest some properties later when discussing
the type system.
```mathjax
\begin{array}{rcl}
\textit{program}
&=& \textit{interaction}_1, ~\ldots,~ \textit{interaction}_k\\[0.25em]
\textit{ref}
&=& \textbf{named}~\textit{name}~~|~~\textbf{indexed}~i\\[0.25em]
\textit{interaction}
&=& \textbf{def}~\textit{value}\\
&|& \mathbf{name}~\textit{ref}~\textbf{a}~\textit{name}\\
&|& \textbf{dot}~\textit{name}~\textbf{on}~\textit{ref}\\
&|& \textbf{apply}~\textbf{args}~\textit{ref}_1, \ldots, \textit{ref}_n~\textbf{to}~\textit{ref}\\
&|& \mathbf{evaluate}~\textit{ref}\\
&|& \mathbf{abstract}~\textbf{from}~\textit{ref}_1, \ldots, \textit{ref}_k~\textbf{to}~\textit{ref}
\end{array}
```
A $\textit{program}$ is a finite sequence of interactions. To display a program,
we start with an initial empty state and apply the interactions to the current state in a sequence.
A state is a bit like a spreadsheet -- it is a mapping that maps references $\textit{ref}$ to
formulas and, when a formula has been evaluated, also values. We do not give a fully formal
definition of _formulas_ and _values_, but briefly:
- a _reference_ can be just an index or a name. Most interactions create new formulas that
are indexed and the user has the option to name them later;
- a _value_ can be a primitive value (number, boolean or string), an object or an operation;
- a _formula_ can be member access (or an object identified by a reference) or an invocation (of an operation
identified by a reference with multiple arguments, each identified by a reference).
Our system consists of 6 kinds of interactions. The idea of representing programs as interactions
also exists in work on structured editing by [Omar et al. (2017)], discussed in more detail later,
but our interactions are less focused on editing code and more focused on higher-level programming
tasks. The interactions and their effect on the state are:
- $\textbf{def}$ -- defines a new primitive value and adds it to the state using a new
indexed reference as the key. We used this above when defining a string with the file name
or the index of a sample row.
- $\textbf{name}$ -- renames a reference, typically from an indexed one to a named one. We did
this when introducing named variables `aviaData` and `sampleIndex`.
- $\textbf{dot}$ -- creates a new formula with an indexed reference that represents a member
access on an object identified by another reference. We use this when accessing the `load`
member or the `at` member.
- $\textbf{apply}$ -- creates a formula that represents an invocation of an operation. The
arguments $\textbf{args}$ and the operation $\textbf{to}$ are all identified by references.
We used $\text{apply}$ when calling `load` or `at` (with loaded data table as instance and
`sampleIndex` as one and only argument).
- $\textbf{eval}$ -- evaluates a formula specified by a reference and adds the resulting value to
the current program state. The value can then be retrieved as when we looked at a preview of
a table or a row after evaluating it. Evaluation also recursively evaluates all references that
are required for obtaining a value for the specified one.
- $\textbf{abstract}$ -- defines a new operation. We have not used this operation yet, but we
will do this in the next demo. As we'll see, this is done by marking some references in the
current existing state as inputs and outputs.
There are a few additional interactions in the prototype, but the above documents the
important ones. Although we left out details of how individual interactions affect the
program state, it is close to being a full description that one could use to reimplement the
Histogram system. We did not say much about the $\text{abstract}$ interaction and we will rectify
that next.
### _3.3_ Turning formulas into reusable functions
We already discussed one design principle in Histogram -- _prefer choosing over composing_.
The following demo will illustrate another design principle, which is _always let users see
concrete values_. This was, indeed, the case in the previous demo where each formula we added
had a corresponding value. Evaluation is explicit and has to be triggered by the user, but
each formula had a value. How to keep this property becomes an interesting challenge when we
want to let programmers introduce custom operations or _function values_.
> **Try it yourself.**
In the demo, we use the function as an argument to `filter`, but you can also give it a name and
call it directly. To do this, click on the `fun v ->` block, select "name" from the auto-complete
list and enter a name for the function. If you then click on `fun v ->` (again), you should
see a list of values that have a type compatible with the argument of the function and you can
select one to invoke it. This will display only `sampleRow` initially, but you can use `at` to
get other compatible inputs.
The $\text{abstract}$ interaction is perhaps best understood as the _extract function refactoring_.
We first construct the body of the function using concrete input values and then create a function
by marking some of the sub-formulas on which the formula of the body depends as inputs. When
creating a function through our user interface, we click on the block corresponding to the
result and then choose an input from an auto-complete list. The list shows references of all
code blocks that the function depends on. Those are displayed either as name (e.g. `sampleRow`)
when the reference is named or as inline code snippet for anonymous references.
We will discuss how the code-like view of Histogram programs works in more detail in the next section.
However, when displaying a function, we display its body and replace the input reference with a variable
name such as `v`. This is familiar to expert programmers, but it is not how functions are
represented internally -- the $\text{abstract}$ interaction does not copy the body of the
function (as extract function refactoring would). It merely records the references of its inputs
and output. The concrete input values are also not lost. We can select and evaluate blocks inside
the body of the function and we get a value computed based on the inputs that we used when
constructing the body of the function.
**_4._ Environments**: Two ways of looking at programs
------------------------------------------------
Earlier in this essay, we discussed how data analysts use Jupyter notebooks to write Python
code. However, a lot of simpler data analytical tasks are done using spreadsheet systems like
Excel. On one hand, spreadsheets are extremely easy to use for simple tasks, but they are limited
in what they can do. On the other hand, you can do almost anything in a Jupyter notebook, but
even a simple language like Python requires significant programming skills. There is a _tooling
gap_ between spreadsheets and programming tools, meaning that one cannot easily transition from
one to the other. The approach that we use in Histogram has a potential to bridge this gap.
### _4.1_ Editing Histogram programs as code
The Histogram language does not have a fixed syntax. Programs are represented as lists of
interactions. It is not expected that programmers will directly write such lists. Instead, we
typically work with a state that maps _references_ to _values_ or _formulas_. Such state is
obtained by applying individual interactions to an initial empty state.
In the above demos, we used a Histogram programming environment that displays the current state
as source code and lets you add new interactions through a mechanism akin to auto-complete.
As we will see in the next demo, this is not the only possible way of displaying Histogram
programs, but first we discuss how the earlier code-like environment works.
As discussed earlier, the Histogram program state is a mapping from references to formulas
and optional values for those references that have been evaluated. A formula can be a member
access or an invocation. Importantly, all arguments of a formula are represented as references
and so the representation of formulas in the state is not recursive. When displaying the state
as code, we turn the flat _formulas_ into nested _expressions_ as follows:
- We construct an expression for all references that are either named (represented as a
`let` binding) or references that are not referenced by any other formula in the state
(represented as `do[n]` bindings where `n` is the index of the reference).
- When doing the above, we do not look inside functions, so a formula that is used as part
of a function will also appear independently, outside of the expression that represents
the function.
- To construct an expression from a formula, we follow the references inside a formula.
We display named references as variables and we follow indexed references recursively
and inline their formula in the place where they are used.
One consequence of the above approach is that formulas that are not named may appear multiple
times in the displayed source code. You can see this in the previous demo in step 4 -- when
we access the `filter` operation on the expression `data.load("data/avia.csv")`, the expression
that loads the data is duplicated. This is the same formula with the same reference but displayed
in two different places. If you hover over it, you will see that the environment also highlights
both of the occurences of the formula. The same happens when we hover over a formula inside a
function, because those are also displayed twice. One interesting problem is how should the
environment behave when the programmer starts editing formula that appears in multiple places.
We return to this issue in the future work section.
### _4.2_ Editing Histogram programs in a spreadsheet
In the following demo, we construct the same program as above -- a visualization showing total
number of deaths in air traffic accidents per year. This time, the analysis is done in a
programming environment that looks more like a spreadsheet. To do this, we do not need to
change the representation of Histogram programs. A program is still a list of interactions and
a state is still a mapping from references to formulas or values. We only change the way we
display the state and the user interface through which interactions are triggered.
Note that the following is quite far from a traditional spreadsheet in two ways. First, cells
in the table display formulas rather than values as a typical spreadsheet does. To see a value,
you have to click on a cell and look at the preview panel. Second, the locations of formulas
in the spreadsheet is determined automatically and a user cannot move them. We discuss ways of
addressing those limitations in the future work section. That said, our current limited prototype
is a first step towards closing the gap between spreadsheets and programming tools.
> **How does it work?** Each formula is located in a single cell. References are displayed as
spreadsheet-like references on a two-dimensional grid. The spreadsheet shows code, while panels on
the right display values and let you interact with the system.
> **Try it yourself.**
You can experiment with the spreadsheet view in the same way as with the code view.
For example, load the `data/rail.csv` file with information on rail accidents and
compare rows at indices 3025 and 3018 showing the number of rail passengers killed
in France and Germany.
As mentioned above, the spreadsheet view of a Histogram program displays the state in the
form of formulas, rather than displaying the evalauted data. This would be more familiar, but
it raises interesting problems, such as how to display a large data table in a single cell.
We return to this topic in [section 7.2](#s7_2). When displaying Histogram program in a
spreadsheet, we use the same state as when displaying it as code, but we proceed differently.
Rather than constructing nested expressions, we keep the flat structure of formulas. We replace
both indexed and named references with a location in the spreadsheet.
The view is constructed as follows:
- Formulas that represent a member access or an application are placed below a cell that
contains the object or operation, but only when there are no other formulas using the same
object or operation.
- If a formula is referenced from multiple other formulas, then the formulas are placed at
the top of a new column. Note that when we add new formula, a single column may be split
into multiple new columns, because a formula that has been previously referenced just once
may now be referenced multiple times.
- All primitive values, including numbers, strings and also functions, that are used as
arguments of other operations, are placed in the first column. When we access a member of
such primitive or invoke such operation directly, it will be moved to a new column.
When displaying a formula in a cell, we display the value of primitive values and operations.
For other types of formulas, we display the code that they represent. Generally, we do not
build nested expressions with one exception. In the above demo, we have `data` in B1; we have
a value representing the `load` operation in B2 and we invoke the operation in B2 with A1 as
an argument in cell B3. This is displayed as `B1.load(A1)` in B3, but the internal representation
in cell B3 is actually `B2(A1)`. To make the displayed code more readable, we check the contents
of B2 and, if the cell contains a member access, we display the invocation in a way that looks
like a method call. We expect that treating operations as first-class values might not be obvious
and so our view hides this, even though that is what happens internally.
### _4.3_ Creating programs with direct manipulation
When using a spreadsheet system such as Excel, you do not need to write code. Instead, many
tools for manipulating data in the spreadsheet are exposed through user interface. This way
of interacting with systems is known as direct manipulation user interfaces and has been
recognised and developed by ([Shneiderman, 1981](#refs)). Such interfaces are easy to use,
but they are not always transparent. Many operations in a spreadsheet system like Excel will
modify the data in the spreadsheet, without leaving a trace of how this has been done.
In Histogram, we can support similarly easy ways of manipulating data for kinds of data that
have a preview like data tables. However, we can keep the accountability and transparency that
we get by representing those as programs. The key idea is that a preview can be interactive and
using the user interface can trigger interactions that will then be added to the program.
This is similar to the idea of the Sketch-n-sketch system ([Chugh et al., 2016](#refs)), which
uses a different program representation to achieve a similar effect.
In our prototype, we implement a direct manipulation user interface for data tables. When a
Histogram formula evaluates to a data table, you can not only see the data, but also filter
it, sort it and index into it directly through the user interface.
> **How does it work?** The next demo is non-interactive, because this
allows us to show mouse cursor location and interactions with standard operating
system controls. The image data for this demo are quite large (60MB) and so it might take
some time to load.
> **Try it yourself.**
The above demo is not interactive, but you can fully replicate it in one of the earlier playgrounds.
Just scroll up and try exploring data on your own. Note that you can use both the code view and the
spreadsheet view, so you can use either of the two!
The fact that Histogram represents programs as lists of interactions makes implementing the above
interface easy. The code in the preview does not have to laboriously transform the source code of
the program and insert code corresponding to the actions made by the user. Instead, it is provided
with a reference representing the data table and it triggers a number of interactions.
Consider the case when we click on a row index $4$ in a data table and the preview triggers
interactions that add a call to `at(4)` and evaluate it. The preview code is provided with a
reference $r$ that represents the data table and an object $e$, which represents the editor
environment. We can add interactions by calling the $\textit{interact}$ operation on $e$. This
mutates the current list of interactions. When the operation defines a new formula, the operation
also returns a reference to this new formula. Adding `at(4)` is expressed as follows:
```mathjax
\begin{array}{l}
r_1 = e.\hspace{-0.1em}\textit{interact}\,(\textbf{def}~4)\\
r_2 = e.\hspace{-0.1em}\textit{interact}\,(\textbf{dot}~\text{"}\hspace{-0.23em}\text{at}\hspace{-0.25em}\text{"}~\textbf{on}~r)\\
r_3 = e.\hspace{-0.1em}\textit{interact}\,(\textbf{apply}~\textbf{args}~r_1~\textbf{to}~r_2)\\
e.\hspace{-0.1em}\textit{interact}\,(\mathbf{evaluate}~r_3)
\end{array}
```
Our prototype lets users undo and redo interactions by using the back and forward buttons in the
upper right corner of the interactive components. This makes it possible to see the individual
interactions that an action in a user interface triggers. This can help users who are not
programmers learn how to use the system:
- One of the ways in which spreadsheet users learn to use advanced features is by examining
existing spreadsheets that use them ([Sarkar and Gordon, 2018](#refs)). Our system supports
this scenario, because the code shows a full trace of what has happened.
- More directly, there is also empirical evidence that direct manipulation, like that implemented
for our data table previews, lowers the barriers to computer programming and supports transfer
learning ([Hundhausen et al., 2009](#refs)).
**_5._ Type system:** Checking based on history
------------------------------------------
Treating programs as lists of interactions has a number of interesting consequences. So far,
we looked at how this changes the way we refactor code into functions and how this enables
interesting user interface capabilities. In this section, we focus on more technical aspect and
discuss the way Histogram checks types.
As discussed earlier, the state that is obtained by applying interactions maps each reference
to a formula and optionally a value. Histogram programs are not evaluated automatically in the
background, so we do not have a value for each reference. We make evaluation explicit to follow
the model used by notebook systems.
In many live programming systems, type system may not provide much additional value, but there
are two reasons for having a type system in Histogram. First, code is not executed automatically
and so we can use types to check code when it is being constructed and prevent users from
creating programs that would fail later. Second, we use type information for computing suggestions
in the auto-complete lists, both when offering members and when offering possible arguments of
an operation. We first discuss how Histogram types guarantee correctness and then look at an
interesting interaction between types and the evaluation interaction.
### _5.1_ Well-constructed programs do not go wrong
There are a number of ways in which Histogram programs can be incorrect. For example, we a program
could try to access a non-existent member of an object or attempts to apply arguments to a value
that is not a function. Histogram uses types to prevent those, but our way of using types is a
bit different than in traditional languages.
Most languages (recursively) type check the abstract syntax tree of a program. In Histogram, we
could analogously (recursively) type check formulas that are produced by applying individual
interactions to a state. However, we do not need to do this and we instead just type check the
interactions themselves. If we apply only well-typed interactions to an initial empty state, the
program will always be correct. Interestingly, this way of program construction was termed
_inferential programming_ by [Scherlis and Scott (1983)](#refs), but never further developed.
We do not formally describe the type system in this essay, but we sketch the important details.
Histogram supports a fairly standard set of types. There are three primitive types, a type for
operations and a type for objects with members. It is worth noting that our handling of objects is
structural rather than nominal and we do not support union types:
```mathjax
\begin{array}{rcl}
\textit{type}
&=& \textit{number} ~~|~~ \textit{string} ~~|~~ \textit{boolean} \\
&|& \{ \textit{name}_1\!:\!\textit{type}_1, \ldots, \textit{name}_n\!:\!\textit{type}_n \}\\
&|& (\textit{name}_1\!:\!\textit{type}_1, \ldots, \textit{name}_n\!:\!\textit{type}_n) \rightarrow \textit{type}
\end{array}
```
When checking a program, we track the types of references that were defined by earlier interactions,
which then form the assumptions of our typing judgements. There are two kinds of judgements -- one
for interactions that do not create a new formula (1), such as $\text{evaluate}$, and one for
interactions that do (2), such as $\text{dot}$. The former ones just check that an interaction is
well-typed, while the latter ones also synthesize a type for the new reference:
```mathjax
\begin{array}{lcl}
\textit{ref}_1\!:\!\textit{type}_1, \ldots, \textit{ref}_n\!:\!\textit{type}_n \vdash \textit{interaction}&\qquad&(1)\\
\textit{ref}_1\!:\!\textit{type}_1, \ldots, \textit{ref}_n\!:\!\textit{type}_n \vdash \textit{interaction}\Rightarrow\textit{type}&\qquad&(2)
\end{array}
```
This way of designing the type system has two interesting consequences. First, when the user is
creating a program, we can check it efficiently on the fly. All interactions operate on references
for which we already have types, so it is also easy to infer types for new references. This is
also the case for operations -- the $\text{abstract}$ interaction creates an operation from an
existing computation and so Histogram knows the types of the inputs. Second, the fact that we only
need to type check interactions means that the user interface through which interactions are
invoked can only offer well-typed ones ones.
Our prototype, indeed, only exposes valid interactions in the auto-complete. There are three kinds
of interactions where checking needs to be done. Our system lets the user (i) trigger $\text{dot}$
interactions with the names of all possible members for each reference that is of a record type;
(2) trigger $\text{apply}$ interactions with all possible matching references as arguments for each
reference that is of an operation type; and (3) trigger $\text{abstract}$ interactions with all
possible input references for any selected output reference.
The way in which interactions are offered in the user interface could be formally specified as an
interaction synthesis relation. Aside from proving that it only offers valid interactions, we
could also prove that it offers all possible interactions. We leave this as future work and
instead focus on one interesting aspect of how the $\text{evaluate}$ interaction interacts with
the type system.
### _5.2_ Refining types based on values
In all the earlier interactive demos, we used the `data.load` operation to load a CSV file from
a given (relative) URL. The `load` operation can load any CSV file and it does not know anything
about the two specific CSV files used in the demos. When we later accessed columns in the data
table, we did so by ordinary member access. For example, in the first demo, we loaded the `data/avia.csv`
file, accessed the row at index 2529 and then obtained the value in the `2015` column just by
choosing `2015` from the auto-complete list, which contained all columns available in the file.
How does Histogram achieve this?
The trick is that the $\text{evaluate}$ interaction can change the type of a reference. When a
program just constructs code that calls `data.load("data/avia.csv")`, the type of the result will
be an untyped data table where you can only access columns dynamically based on a name stored as
a string. However, if a program also includes an interaction that evaluates the call to `load`,
the type changes to a typed data table where columns are exposed as members. The following demo
illustrates this behaviour by looking at two rows that represent the
2015 [Germanwings Fligth 9525 crash](https://en.wikipedia.org/wiki/Germanwings_Flight_9525)
and the 2001 [Linate Airport disaster](https://en.wikipedia.org/wiki/Linate_Airport_disaster).
The idea that evaluation can affect types of a program may seem unconventional at first, but this
is just a matter of perspective. A Histogram program is a list of interactions and evaluation is
one such interaction. The type of a value represented by a reference thus only depends on the
interactions -- or parts of a program -- involving the reference.
The way this behaviour is implemented in Histogram is quite simple. Each library, such as the one
providing the global `data` value can define a \textit{refine} function that looks as follows:
```mathjax
\textit{refine} : \textit{type} \times \textit{value} \rightarrow \textit{type}
```
When processing the $\text{evaluate}$ interaction, Histogram computes the value for a specified
reference, stores it as part of the current program state and invokes the $\textit{refine}$
function to obtain a new more specific type for the reference. In our prototype, the types
returned by the $\textit{refine}$ operation are always subtypes of the original type and so
this preserves the property that programs created using well-typed interactions remain well-typed.
### _5.3_ User experience of type refinement
Furthermore, the user experience that is made possible thanks to our approach is, in fact,
familiar in a number of existing developer environments. Recall the motivating example
of using the pandas library in a Jupyter notebook to load and process data. Python defers all
checking to runtime, but the way you typically interact with the system is that you write code to
load an input file (or a sample input file), run it and only then continue writing code to process
it. In our example, we only wrote `raw.value` after we run code to load the `raw` data table and
after we saw the available columns in the preview. Histogram captures this way of working and
makes it an inherent part of its type system.
Another case of similar user experience is when writing JavaScript code in the console window of
[Firefox Developer tools](https://developer.mozilla.org/en-US/docs/Tools). When you type
`"test".length` followed by a `.` you get a completion list with members of a number value. However,
if you define a function `length` that returns the `length` member of its arguments and type
`length("test")` followed by a `.` you do not get any suggestions. The difference is that, in
the first case, the editor silently evaluates the code, because it assumes this will not have
unexpected consequences, but in the second case, it does not. This is a somewhat ad-hoc decision
made by the tool authors and Histogram provides a more principled way of capturing it.
Finally, our approach is also related to the way type providers ([Syme et al. 2013](#refs), [Christiansen, 2013](#refs))
work. Type providers execute code at compile-time to generate static types from external data
sources. They can also take static parameters such as database name or service URL, but those have
to be constants that are known at compile-time. Provided types are then used to generate
auto-complete suggestions when writing code. Type providers are similar to the way Histogram works
in that some code is evaluated in order to give more precise type information. However, type
providers are limited to a two-stage way of working -- they run at compile-time and can only depend
on constant parameters. The mechanism in Histogram can be seen as a generalisation that supports
multiple stages. This can be useful in data science scenarios that dynamically transform data and
might, for example, drop certain columns dynamically based on the values they contain.
**_6._ Implementation:** Building an interactive essay
------------------------------------------------------
Before discussing the design choices and future work, it is worth adding a few notes on how has
this interactive essay been implemented. This essay uses the capabilities provided by the web
to allow the reader to experience some aspects of the design of the Histogram system. We believe that
this way of presenting the work lets us focus on the important aspects of our work -- rather than
developing theoretical foundations of Histogram or conducting user studies, we want to communicate
the style of interaction and some of the consequences of our system design. This essay thus follows
some of the ideas discussed in a recent position paper on evaluating programming systems design
by [Edwards et al. (2019)](#refs).
The code behind the present essay is available [on GitHub](https://github.com/tpetricek/histogram).
The implementation is written in F# and uses the [Fable compiler](https://fable.io) to compile
it into JavaScript. One technically interesting aspect of our implementation is how the
scrollytelling effect is implemented, especially because our approach could be likely reused in
other similar essays.
Our system uses the Elm architecture, also known as model-view-update ([Czaplicki et al., 2019](#refs))
where a user interface consists of a type representing the current state (model) together with a
type representing events (updates) that can occur in the user interface, a function that updates
the current state when an event occurs and a function that can render the current state.
In our case, the model type includes the Histogram program and various properties of the user
interface. The updates include various user interface events to highlight and select references in
the Histogram program and choose items in a menu, but also an event that represents a Histogram
interaction as defined in section 3.2. The interactive demos in this essay are represented simply
as lists of events that are passed to the update function of our system as the reader scrolls
through the page. We want to show what interacting with the prototype user interface looks like
and so those events include both Histogram interactions and also other user interface events.
Although our current implementation is not directly reusable, the general pattern of using
Elm architecture, representing demos as lists of events and exposing them via scrollytelling
seems to be an easy to reuse method for building interactive essays.
**_7._ Remarks:** Design choices and future work
------------------------------------------------
This essay does not aim to present a fully developed and functional programming system. Instead,
it should be seen as an exploration of ideas in a certain design space. As such, it leaves many
open questions, unexplored links and possible directions for future work. In this section, we
briefly review some of those.
### _7.1_ From constructing to editing
The most obvious limitation of our system is that it does not allow the user to modify a program
once it has been constructed. You can create a program, but the only way of changing it is to
undo interactions and redo them differently. This lets users correct small mistakes, but it is
inadequate for a real-world system.
There are several ways in which editing of programs could be supported. We could either rewrite the
history and treat program edits as meta-interactions, or we could add new kinds of interactions to
represent different edit operations. In the future, we plan to explore the latter approach, but
both of these pose the same interesting problem. Program edits can make programs (at least
temporarilly) invalid. This can be addressed by introducing holes as done by Hazel
([Omar et al., 2019](#refs), [Omar et al., 2017](#refs)), but our program representation allows
another possible approach.
Imagine that we add an interaction that removes a formula at a given reference. We can keep
the displayed program valid and so we also recursively remove all formulas that depend on the
one removed by the user. This can remove quite a lot of code, but this code is not lost. The
environment knows about it, because it is a part of the history and it could then offer the user
to restore the temporarily removed code once the errors caused by the initial deletion are
resolved. The user experience of this approach remains to be investigated, but we believe this
might be a compelling (or a complementary) alternative to an approach based on holes.
### _7.2_ Simplifying the spreadsheet interface
Our prototype comes with a somewhat more programmer-focused code-based interface and a somewhat
more user-focused interface akin to a spreadsheet. Both of these could be further improved to
better support their respective users. Our spreadsheet view displays code in cells, whereas a
typical spreadsheet displays values. We could do this for references that have been evaluated,
but many of our values would not fit in a single spreadsheet cell and we would need to be able
to map a reference to a range in the spreadsheet. We could then display a data table or a row
as an actual data table in the spreadsheet. There are other values that might not be easy to
display in a spreadsheet such as operations -- we briefly discuss these in section 6.5. Finally,
our spreadsheet uses automatic layout and it would be interesting to find ways of giving the user
(more) control over how this is done.
### _7.3_ Experts and keyboard-based interactions
A complementary problem is how to better serve expert users. Our current prototype can display
programs as code, but the interactions with those are through an arguably cumbersome user interface.
An appealing alternative would be to offer a command prompt where programmers can enter
interactions using a keyboard. This could be made efficient by using suitable shortcuts and
auto-complete. Interestingly, this way of interacting with the system is somewhat similar to
the way in which thorem provers like Coq ([Barras et al., 1997](#refs)) work. To prove a theorem
in Coq, one invokes a series of tactics that transform the proof obligations. A proof is
a list of tactic invocations, which is similar to our case where a program is a list
of programming interactions.
### _7.4_ Histogram programs as Histogram values
In a recent discussion, [Basman et al. (2018)](#refs) and [Petricek (2018)](#refs) discuss how
to design a programming substrate, or programming environment, that would enable open authorship,
i.e. allow the users to gradually progress from using a system to making small changes and,
eventually, to modifying the system itself. Smalltalk [(Goldberg and Robson, 1983)](#refs) is a
canonical example of a system that can be modified through itself, although this requires expert
programming skills.
The current Histogram prototype is very simple and does not even let you create new objects such
as the built-in `data` value. However, it is interesting to consider how this could be changed.
The first interesting step would be to make a Histogram program, i.e. the list of interactions a
value that could, itself, be edited and modified in the Histogram environment. More specifically,
we could represent individual interactions as members that are invoked on an object that
represents the program. This could make Histogram more powerful by enabling an interesting form
of meta-programming in the language.
### _7.5_ Lowering the cost of abstraction
Finally, the current Histogram prototype makes it easier to construct functions by starting with
concrete data, writing code to process it and then extracting a function by choosing some inputs
as parameters. This is more concrete than writing a function in a traditional programming language,
but we are still left with conceptually challenging function values in our program. We would like
to make this experience more akin to using the "copy down" functionality in Excel that copies a
formula to a table of inputs.
One possible approach is to use something akin to linked editing ([Toomim et al., 2014](#refs)) or
managed copy-and-paste as known from Subtext ([Edwards, 2006](#refs)). This would make it possible to reuse the
same code in multiple contexts, perhaps with modifications. It would also fit well with our
approach as copy-and-paste could be just another kind of interaction. Another approach would be
to represent functions as hypothetical interactions -- a function constructed from a concrete
computation would be a sequence of interactions that copy its arguments to the input references,
followed by an evaluate interaction and an interaction that copies the result back to a reference
specified by the caller. This is, in fact, how our current prototype implements functions, but
we do not currently expose this to the user.
### _7.6_ Exploring the design space
This essay should be primarily seen as an exploration of design space in the sense discussed by
[Edwards et al. (2019)](#refs). We choose simple data exploration as our problem domain and the idea
of representing programs as lists of interactions as our starting point. We then followed a path
towards a minimal demo-able prototype, making a number of design decisions along the way.
Numerous related projects occupy a similar space, but makes different design decisions.
In Subtext ([Edwards, J., 2005](#refs)), programmers interact with trees and treats copying
as a central operation; work on direct programming ([Edwards, J., 2018](#refs)) moves towards
unifying program and data in a way where both can be edited by direct manipulation.
Hazel and Hazelnut ([Cyrus et al., 2019](#refs), [Cyrus et al., 2017](#refs)) is a structured
programming environment with a calculus of interactions at its core, but with focus on editing
incomplete programs represented as abstract syntax trees.
Our work briefly explored the idea of editing code via direct manipulation with a preview. We
did so via a mechanism where user interface can trigger interactions, which are then added to
the program. The Sketch-n-Sketch project ([Hempel et al. 2019](#refs)) takes the idea of direct
manipulation much further and explores ways of synthesizing program updates to synchronize the
code and preview ([Chugh et al. 2016](#refs)). This can be captured using the notion of
bidirectional evaluation ([Mayer et al., 2018](#refs)).
**_8._ Conclusions:** Glimpse of the future
-------------------------------------------
Every now and then, somebody remarks that all programming languages have already been invented
or, at least, that we have already explored most of the interesting corners of the desing space
for programming languages. The purpose of this essay is to show that there still are unexplored
corners and that we can make relatively simple but design decisions that will have interesting
consequences.
The key idea in this essay was to represent programs as lists of interactions that were used to
create the program. This way, we want to shift focus from thinking about _programs_ to thinking
about _programming_. The key concepts of a programming language stop being different kinds of
expressions, but rather operations such as refactoring, the use of auto-complete and interactive
evaluation of part of code.
We explored the idea in the context of a simple programming environment for data exploration.
Our way of representing programs has a number of interesting consequences. If we construct
functions via a refactoring, we can keep the original inputs as sample values for previews;
if we include evaluation as an interaction, our type system can give more precise information
for parts of program that have been evaluated. Our way of representing programs also enables
valuable user interface features. We can display the same program both as source code and as
a spreadsheet and we can easily let users construct programs by directly manipulating data in
previews.
As the quote by Carl Sagan that we borrowed for the title of this essay says, "You have to know
the past to understand the present". When it comes to programs, knowing their past might not be
strictly necessary for understanding their present, but it certainly enables a range of interesting
user experiences that is worth a further study or, perhaps, even a new programming paradigm.
References
----------
1. Aaron, S., & Blackwell, A. F. (2013). _From sonic Pi to overtone: creative musical experiences with domain-specific and functional languages_. In Proceedings of the first ACM SIGPLAN workshop on Functional art, music, modeling & design (pp. 35-46). ACM.
1. Barras, B., Boutin, S., Cornes, C., Courant, J., Filliatre, J. C., Gimenez, E., Herbelin, H., Huet, G., Munoz, C., Murthy, C., et al. (1997). _The Coq proof assistant reference manual: Version 6.1_. Research Report RT-0203, INRIA. 1997,pp.214.
1. Basman, A., Tchernavskij, P., Bates, S., & Beaudouin-Lafon, M. (2018). _An anatomy of interaction: co-occurrences and entanglements_. In Conference Companion of the 2nd International Conference on Art, Science, and Engineering of Programming (pp. 188-196). ACM.
1. Burnett, M. M., Atwood, J. W., & Welch, Z. T. (1998). _Implementing level 4 liveness in declarative visual programming languages_. In Proceedings. 1998 IEEE Symposium on Visual Languages (Cat. No. 98TB100254) (pp. 126-133). IEEE.
1. Christiansen, D. R. (2013). _Dependent type providers_. In Proceedings of the 9th ACM SIGPLAN workshop on Generic programming (pp. 25-34). ACM.
1. Chugh, R., Hempel, B., Spradlin, M., & Albers, J. (2016). _Programmatic and direct manipulation, together at last_. In ACM SIGPLAN Notices (Vol. 51, No. 6, pp. 341-354). ACM.
1. Czaplicki, E. and contributors (2019). _The Elm Architecture_. Available online at [https://guide.elm-lang.org/architecture/](https://guide.elm-lang.org/architecture/)
1. DeLine, R., Fisher, D., Chandramouli, B., Goldstein, J., Barnett, M., Terwilliger, J. F., & Wernsing, J. (2015). _Tempe: Live scripting for live data_. In VL/HCC (pp. 137-141).
1. Edwards, J. (2006). _First Class Copy & Paste_. Computer Science and Artificial Intelligence Laboratory Technical Report, MIT-CSAIL-TR-2006-037
1. Edwards, J. (2005). _Subtext: uncovering the simplicity of programming_. In ACM SIGPLAN Notices (Vol. 40, No. 10, pp. 505-518). ACM.
1. Edwards, J. (2018). _Direct programming_. In proceedings of the 29th Annual Workshop of the Psychology of Programming Interest Group, PPIG 2018. Available online at [https://vimeo.com/274771188](https://vimeo.com/274771188)
1. Edwards, J., Kell, S., Petricek, T., Church, L. (2019). _Evaluating programming systems design_. To appear in proceedings of the 30th Annual Workshop of the Psychology of Programming Interest Group, PPIG 2019
1. Goldberg, A., & Robson, D. (1983). _Smalltalk-80: the language and its implementation_. Addison-Wesley Longman Publishing Co., Inc..
1. Hempel, B., Lubin, J., and Chugh, R. (2019). _Sketch-n-Sketch: Output-Directed Programming for SVG_. In Proceedings of the ACM Symposium on User Interface Software and Technology (UIST), New Orleans, LA, October 2019.
1. Hundhausen, C. D., Farley, S. F., & Brown, J. L. (2009). _Can direct manipulation lower the barriers to computer programming and promote transfer of training?: An experimental study_. ACM Transactions on Computer-Human Interaction (TOCHI), 16(3), 13.
1. Kluyver, T., Ragan-Kelley, B., Pérez, F., Granger, B.E., Bussonnier, M., Frederic, J., Kelley, K., Hamrick, J.B., Grout, J., Corlay, S. & Ivanov, P. (2016). _Jupyter Notebooks-a publishing format for reproducible computational workflows_. In ELPUB (pp. 87-90).
1. Ludäscher, B., Altintas, I., Berkley, C., Higgins, D., Jaeger, E., Jones, M., ... & Zhao, Y. (2006). _Scientific workflow management and the Kepler system_. Concurrency and Computation: Practice and Experience, 18(10), 1039-1065.
1. Maloney, J. H., & Smith, R. B. (1995). _Directness and liveness in the morphic user interface construction environment_. In ACM Symposium on User Interface Software and Technology (Vol. 95, pp. 21-28).
1. Mayer, M., Kunčak, V., and Chugh, R. (2018). _Bidirectional Evaluation with Direct Manipulation_. In Proceedings of the ACM on Programming Languages (PACMPL), Issue OOPSLA, Boston, MA, November 2018.
1. McDirmid, S. (2013). _Usable live programming_. In Proceedings of the 2013 ACM international symposium on New ideas, new paradigms, and reflections on programming & software (pp. 53-62). ACM.
1. McDirmid, S. (2007). _Living it up with a live programming language_. In ACM SIGPLAN Notices (Vol. 42, No. 10, pp. 623-638). ACM.
1. McKinney, W. (2011). _pandas: a foundational Python library for data analysis and statistics_. Python for High Performance and Scientific Computing, 14.
1. Omar, C., Voysey, I., Chugh, R., & Hammer, M. A. (2019). _Live functional programming with typed holes_. Proceedings of the ACM on Programming Languages, 3(POPL), 14.
1. Omar, C., Voysey, I., Hilton, M., Aldrich, J., & Hammer, M. A. (2017). _Hazelnut: a bidirectionally typed structure editor calculus_. ACM SIGPLAN Notices, 52(1), 86-99.
1. Petricek, T. (2018). _Critique of 'An anatomy of interaction: co-occurrences and entanglements'_. In Conference Companion of the 2nd International Conference on Art, Science, and Engineering of Programming (pp. 197-201). ACM.
1. Petricek, T., Guerra, G., & Syme, D. (2016). _Types from data: Making structured data first-class citizens in F#_. In ACM SIGPLAN Notices (Vol. 51, No. 6, pp. 477-490). ACM.
1. Sandewall, E. (1978). _Programming in an interactive environment: the LISP experience_. ACM Computing Surveys, 10(1), 35-71.
1. Sarkar, A., Gordon, A. (2018). _How do people learn to use spreadsheets? (Work in progress)_. In Proceedings of the 29th Annual Conference of the Psychology of Programming Interest Group (PPIG 2018), pp28-35.
1. Scherlis, W. L., & Scott, D. S. (1983). _First steps towards inferential programming_. In Program Verification (pp. 99-133). Springer, Dordrecht, 1993.
1. Schiller, J., Turbak, F., Abelson, H., Dominguez, J., McKinney, A., Okerlund, J., & Friedman, M. (2014). _Live programming of mobile apps in App Inventor_. In Proceedings of the 2nd Workshop on Programming for Mobile & Touch (pp. 1-8). ACM.
1. Seyser, D., & Zeiller, M. (2018). _Scrollytelling -- An Analysis of Visual Storytelling in Online Journalism_. In 2018 22nd International Conference Information Visualisation (IV) (pp. 401-406). IEEE.
1. Shneiderman, B. (1981). _Direct manipulation: A step beyond programming languages_. In ACM SIGSOC Bulletin (Vol. 13, No. 2-3, p. 143). ACM.
1. Syme, D., Battocchi, K., Takeda, K., Malayeri, D., & Petricek, T. (2013). _Themes in information-rich functional programming for internet-scale data sources_. In Proceedings of the 2013 workshop on Data driven functional programming (pp. 1-4). ACM.
1. Tanimoto, S. L. (2013). _A perspective on the evolution of live programming_. In Proceedings of the 1st International Workshop on Live Programming (pp. 31-34). IEEE Press.
1. Toomim, M., Begel, A., & Graham, S. L. (2004). Managing duplicated code with linked editing. In 2004 IEEE Symposium on Visual Languages-Human Centric Computing (pp. 173-180). IEEE.
1. Victor, B. (2012). _Inventing on principle_. CUSEC 2012. Available online at: [https://vimeo.com/36579366](https://vimeo.com/36579366)
1. Victor, B. (2012). _Learnable programming? Designing a programming system for understanding programs_. Available online at: [http://worrydream.com/LearnableProgramming/](http://worrydream.com/LearnableProgramming/)