Aho-Corasick string matching in C#
Introduction
In this article I will describe implementation of an efficient Aho-Corasick algorithm for pattern matching. In simple words this algorithm can be used for searching text for specified keywords. Following code is usefull when you have a set of keywords and you want to find all occurences in text or check if any of the keywords is present in the text. You should use this algorithm especially if you have large number of keywords that don't change often, because in this case it is much more efficient than other algorithms that can be simply implemented using .NET class library.
Aho-Corasick algorithm
In this section I'll try to describe the concept of this algorithm. For more information and more exact explanation please take a look at links at the end of article. The algorithm consists of two parts. First part is the building of tree from keywords you want to search for and second part is the searching text for keywords using previously built tree (state machine). Searching for keyword is very efficient, because it only moves through the states in the state machine. If a character is matching it follows goto function otherwise it follows fail function.
Tree building
In the first phase of tree building, keywords are added to the tree. In my implementation I use class StringSearch.TreeNode,
which represents one letter. Root node is used only as a place holder and contains links to other letters. Links created in
this first step represents goto function, which returns next state when character is matching.
During second phase fail and output functions are found. Fail function is used when character is not matching and output function returns found keywords for each reached state. For example in text "SHIS" failure function is used to exit from "SHE" branch to "HIS" branch after first two characters (because third character is not matching). During the second phase BFS (breadth first search) algorithm is used for traversing through all nodes. Functions are calculated in this order, because fail function of specified node is calculated using fail function of parent node.
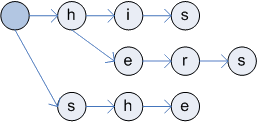
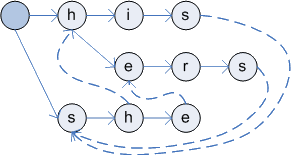
Building of keyword tree (1 - after first step, 2 - tree with fail function)
Searching
As I already mentioned searching means only traversing previously built keyword tree (state machine). To demonstrate how this algorithm works, let's look at commented method which returns all matches of specified keywords:
// Searches passed text and returns all occurrences of any keyword // Returns array containing positions of found keywords public StringSearchResult[] FindAll(string text) { ArrayList ret=new ArrayList(); // List containing results TreeNode ptr=_root; // Current node (state) int index=0; // Index in text// Loop through characters while(index<text.Length) { // Find next state (if no transition exists, fail function is used) // walks through tree until transition is found or root is reached TreeNode trans=null; while(trans==null) { trans=ptr.GetTransition(text[index]); if (ptr==_root) break; if (trans==null) ptr=ptr.Failure; } if (trans!=null) ptr=trans; // Add results from node to output array and move to next character foreach(string found in ptr.Results) ret.Add(new StringSearchResult(index-found.Length+1,found)); index++; } // Convert results to array return (StringSearchResult[])ret.ToArray(typeof(StringSearchResult)); }
Algorithm complexity
Complexity of first part is not so important, because it is executed only once. Complexity of second part is O(m+z) where m is length of the text and z is the number of found keywords (in simple words it is very fast and its speed doesn't drop quickly for longer texts or many keywords).
Performance comparsion
To show how efficient this algorithm is, I created test application which compares this algorithm
whit two other simple methods that can be used for this purpose. First algorithm is using String.IndexOf method to
search the text for all keywords and second algorithm uses regular expressions - for example for keywords he, she and his it
creates regular expression (he|she|his). Following graphs shows results of tests for two texts of different size.
Number of used keywords is displayed on the X axis and time of search is displayed on Y axis.
Interesting thing is that for less than 70 keywords it is better to use simple method using String.IndexOf.
Regular expressions are almost always slower than other algorithms. I also tried compiling test under both
.NET 1.1 and .NET 2.0 to see the difference. Althrough my measuring method may not be very precise it looks that
.NET 2.0 is a bit faster (about 5-10%) and method with regular expressions gives much better results (about 60% faster).
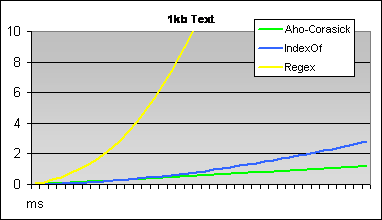
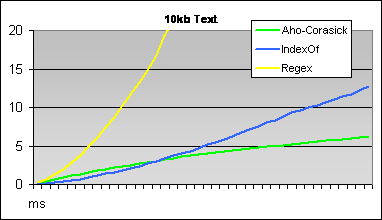
Two charts comparing speed of three described algorithms - Aho-Corasick (yellow), IndexOf (green) and Regex (blue)
How to use the code
I decided to implement this algorithm when I had to ban some words in community web page (vulgarisms etc.). This is typical use case because searching should be really fast, but blocked keywords don't change often (and creation of keyword tree can be slower).
Search algorithm is implemented in file StringSearch.cs. I created interface that represents any search
algorithm (so it is easy to replace it with another implementation). This interface is called IStringSearchAlgorithm
and it contains property Keywords (gets or sets keywords to search for) and methods for searching.
Method FindAll returns all keywords in passed text, FindFirst returns first match.
Matches are represented by StringSearchResult structure, that contains found keyword and its position in the text.
Last method is ContainsAny, which returns true when passed text contains any keyword. Class that implements Aho-Corasick algorithm is
called StringSearch.
Initialization
Following example shows how to load keywords from database and create SearchAlgorithm instance:
// Initialize DB connection SqlConnection conn = new SqlConnection(connectionString); SqlCommand cmd = new SqlCommand("SELECT BlockedWord FROM BlockedWords",conn); conn.Open(); // Read list of banned words ArrayList listWords = new ArrayList(); using(SqlDataReader reader = cmd.ExecuteReader(CommandBehavior.CloseConnection)) { while(reader.Read()) listWords.Add(myReader.GetString(0)); } string[] arrayWords = (string[])listWords.ToArray(typeof(string)); // Create search algorithm instance IStringSearchAlgorithm searchAlg = new StringSearch(); searchAlg.Keywords = arrayWords;
You can also use StringSearch constructor which takes array of keywords as parameter.
Searching
Searching passed text for keywords is event easier. Following sample shows how to write all matches to console output:
// Find all matching keywords StringSearchResult[] results=searchAlg.FindAll(textToSearch); // Write all results foreach(StringSearchResult r in results) { Console.WriteLine("Keyword='{0}', Index={1}", r.Keyword, r.Index); }
Conclusion
This implementation of Aho-Corasick search algorithm is very efficient if you want to find large number of keywords
in text of any length, but if you want to search only for a few keywords it is better to use simple method using
String.IndexOf. Code can be compiled in both .NET 1.1 and .NET 2.0 without any modifications.
If you want to learn more about this algorithm look at the link in the next section, that was very useful for me
during implementation of algorithm and explains theory behind this algorithm.
Links and references
- Set Matching and Aho-Corasick Algorithm [^] - Pekka Kilpeläinen (University of Kuopio)
Future work and history
- (12/03/2005) - First version of this article published at CodeProject
Published: Sunday, 4 December 2005, 12:18 AM
Author: Tomas Petricek
Typos: Send me a pull request!
Tags: .net