Can programming be liberated from function abstraction

When you start working in the programming language theory business, you'll soon find out that
lambda abstraction and functions break many nice ideas or, at least, make your life very hard.
For example, type inference is easy if you only have var x = ..., but it gets hard once you
want to infer type of x in something like fun x -> ... because we do not know what is
assigned to x. Distributed programming is another example - sending around data is easy, but
once you start sending around function values, things become hard.
Every programming language researcher soon learns this trick. When someone tells you about a nice idea, you reply "Interesting... but how does this interact with lambda abstraction?" and the other person replies "Whoa, hmm, let me think more about this." Then they go back and either give up, because it does not work, or produce something that works, in theory, well with lambda abstraction, but is otherwise quite unusable.
When working on The Gamma project and the little scripting language it runs, I recently went through a similar thinking process. Instead of letting lambda abstraction spoil the party again, I think we need to think about different ways of code reuse.
On not adding functions to The Gamma
I wrote about The Gamma project in the last blog post. The goal of the project is to build easy to use programming tools that can be used to build open and reproducible data-driven stories. Rather than including a chart in an article, you should be able to embed a piece of code that gets the data and creates the chart. This way, anyone can see how the data is processed and can also modify and reuse the code. The Olympic medalists visualization illustrates the ideas.
The Gamma implements a simple programming language that runs in the web browser and lets you get the data and build visualizations. It uses type providers for integrating data into the language. In the Olympics visualization, you can get all US and UK medalists for marathon as follows:
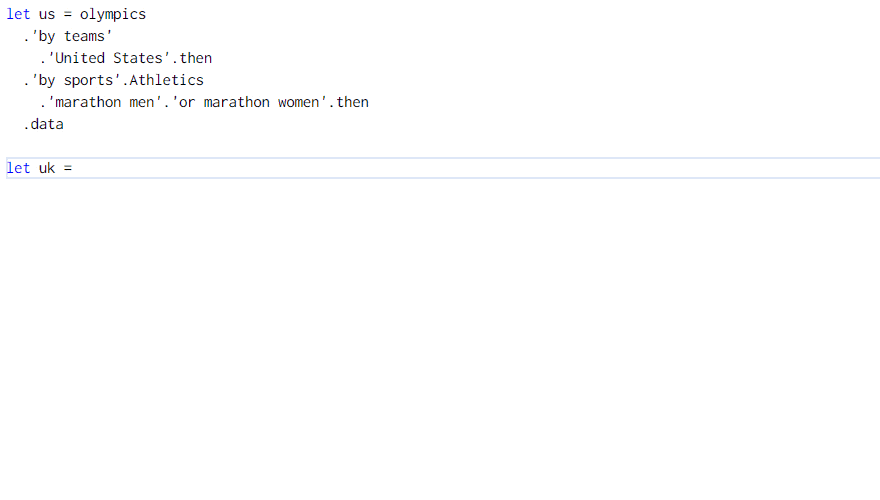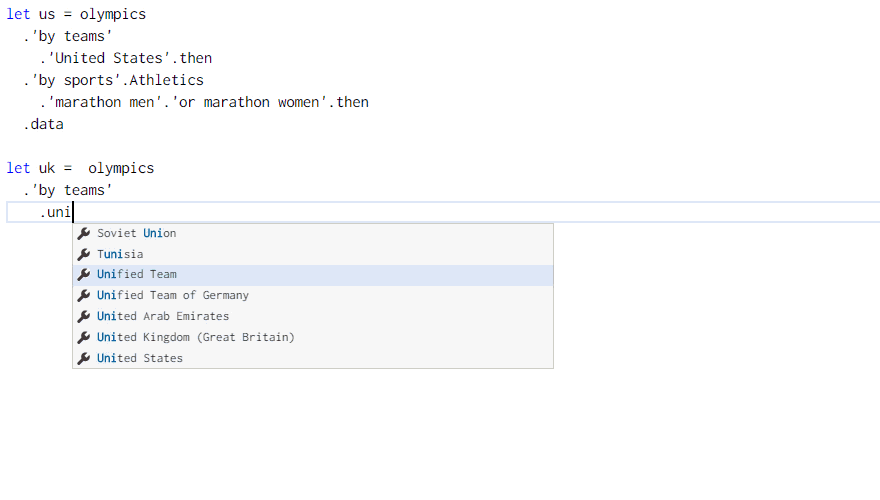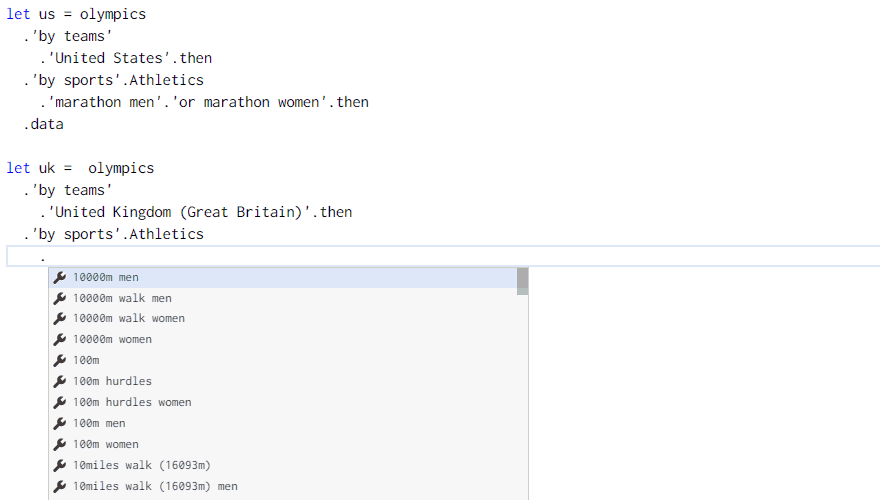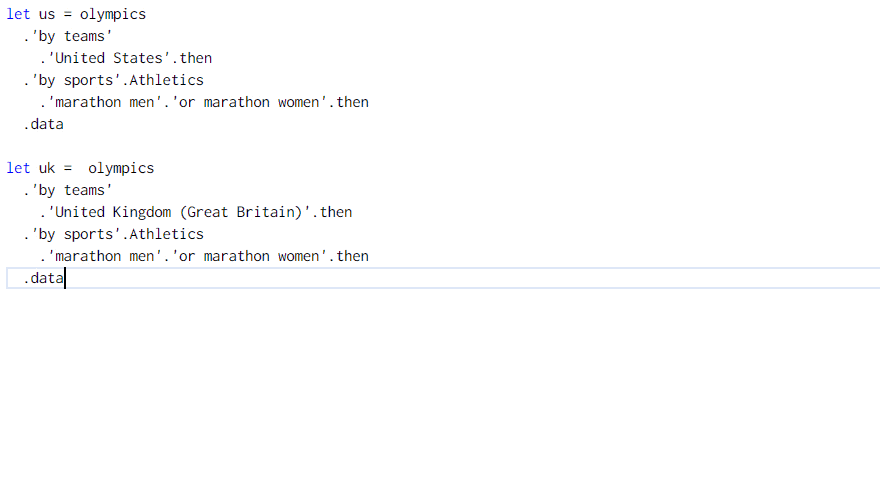
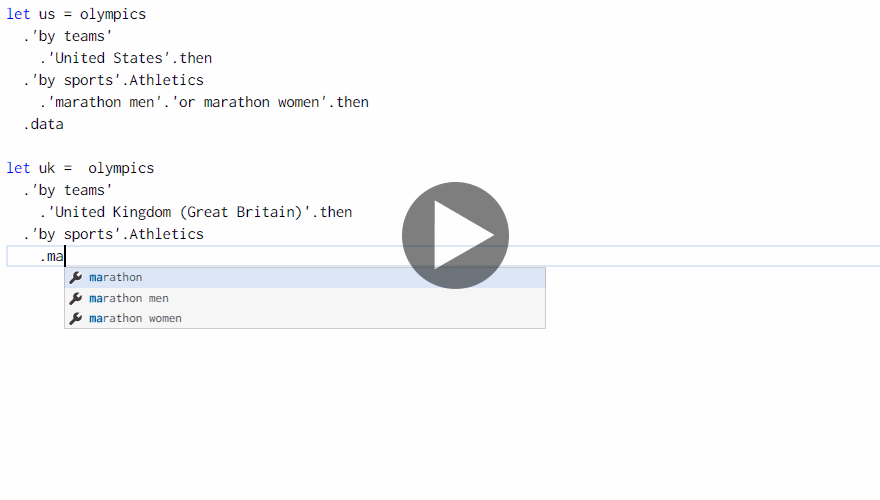
The example shows a case where we might want to use a function to avoid code duplication. Rather than getting the medalists for the two countries and then filtering them by discipline twice, could we write a function to perform filtering by discipline and then call it with data for the two countries?
The obvious answer is to add functions (either named or lambda functions). However, this would break many of the nice features that can work exactly because the language does not have functions.
For the record, I'm mainly thinking about scripting and data analytics and so if you read this article with data analytics in mind, it might make more sense. That said, I think the same ideas would apply to "complex systems" - it just requires more imagination.
What is wrong with function abstraction
Let me go through two examples that illustrate some of the problems with function abstraction. The first one will be using the World Bank type provider in F# Data and it illustrates difficulties with types. The second one is using the Chrome JavaScript console and illustrates difficulties with values.
How functions break type-based tooling
The World Bank type provider lets you easily access information about countries from F#. The
type provider imports country names and available indicators into the type system and so you
can find available data just by typing .. This works beautifully in scripts, but what if
we want to remove code duplication and write a function that returns the GDP (in current
US dollars) for a given country in a given year? This is not so easy:
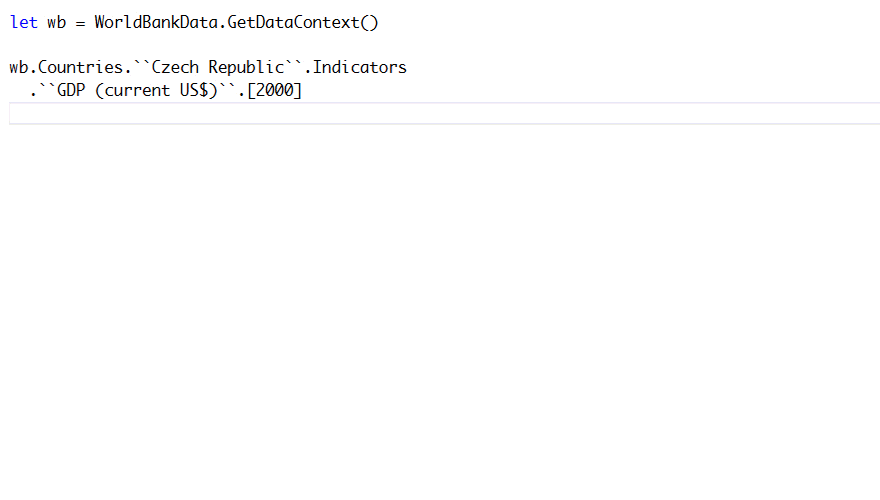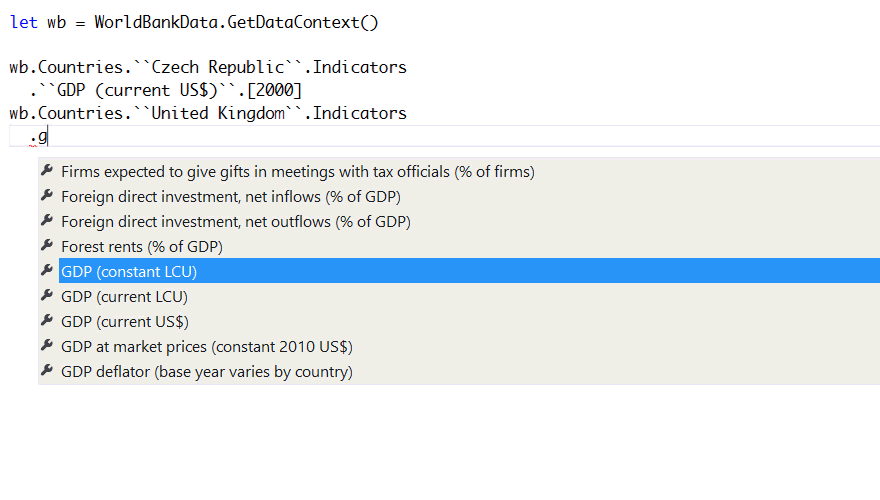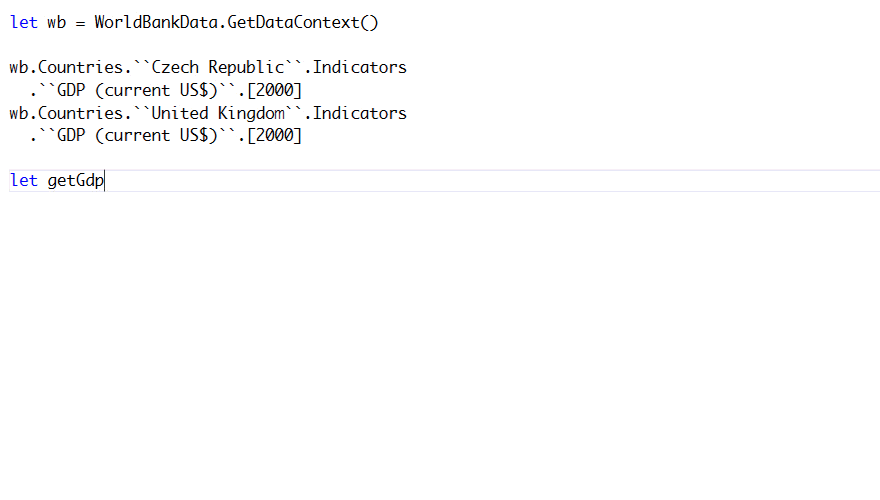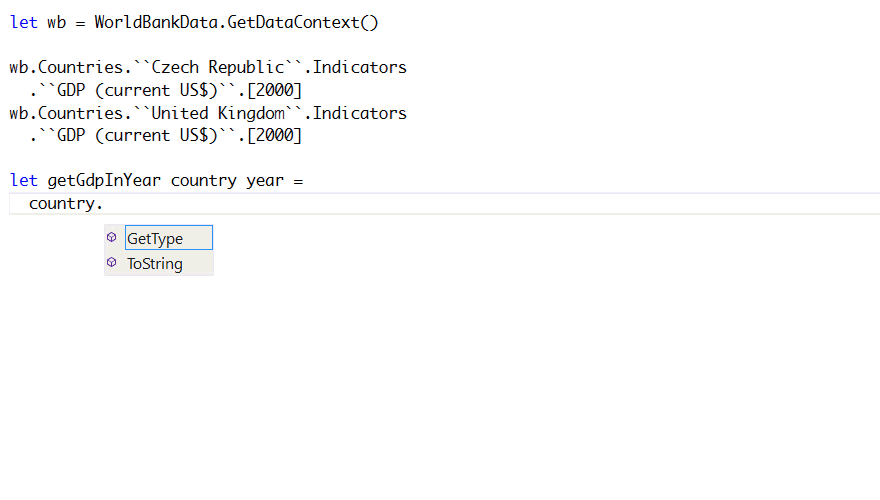
When you define a function taking country and try access the members using ., F# will only
offer you members that all .NET objects have. This is not very useful. Now, there is a number
of options that we have:
-
In F#, you can add a type annotation that specifies the type of
country. With World Bank type provider, the provided type is somewhat hard to find, but it has a name and you can use it. This is harder with some type providers where types of entities do not have obvious names and so finding the right type for a type annotation is not something you'd want to do. -
In languages with structural type system, you could allow the user to access property of any name (say
GDP (current USD)) and infer a type specifying that thecountryvalue needs to have this property. But this means the auto-completion cannot give you any useful hints and you'll only discover typos when you try calling the function - telling you that the name is actuallyUS$and notUSD. -
You could do some more fancy whole-program type inference and deduce the type of
getGdpInYearfrom the later part of the code where you call the function, but this forces you to write the code in an odd order - you need to declare your function, then use it and then go back to actually implement it.
How functions break value-based tooling
I think the F# example illustrates an issue that is not F#-specific, but in case it did not
convince you, let's look at another example. This time, I'm using the Chrome developer console
to extract title of a page and then I want to wrap it into a helper function getTitle:

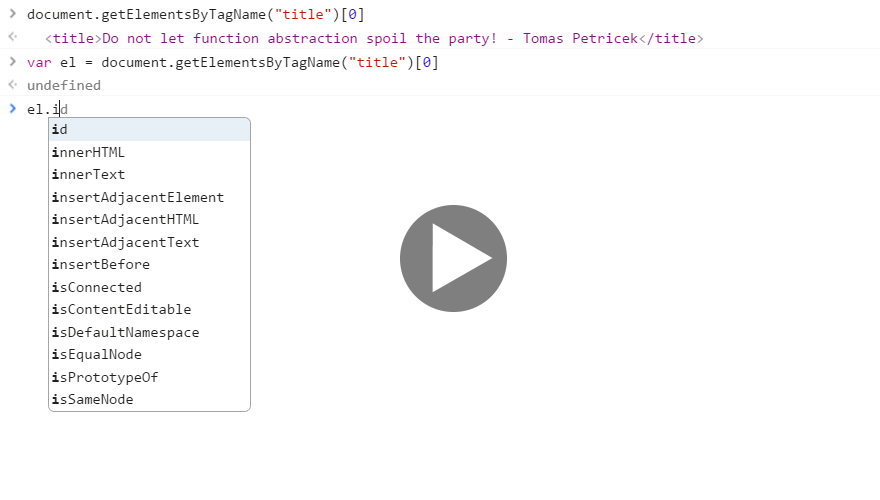
Even though JavaScript is dynamic, Chrome developer tools can give you useful auto-completion
hints. This seems to be based mostly on values. When you have a value el in scope and you type
el. the auto-complete can just give you access to all members of the object. Chrome also uses
various heuristic hints (like name of the variable) and so it sometimes gives you more (or less)
useful hints on other variables.
Is there any chance for making value-based auto-completion to work in presence of functions? I think the best that can be done will inevitably rely on making a best guess. This also means that we do not get other nice things that are possible when we know values of every variable in scope that various live programming systems have (like Sean McDirmid's work or Python tutor project).
In the F# example, the problem with functions is that we do not know the type of their arguments. In the JavaScript example, the problem is that we do not know the value of their arguments. With types, you can give the type explicitly (via annotation). With values, you could give a sample value for primitives (numbers or strings), but I doubt this can be done in a usable way for complex values (say, a chart skeleton).
Abstraction without functions
Looking at the vertical scroll bar, I'm sure you're wondering when am I finally going to offer my alternative solution to this problem. How can we program in a reasonable way without a mechanism similar to functions? I do not have a clear answer, but there is one programming system that has all the properties I would like regular programming languages to have:
- When you have a variable, you always know what is its type and value
- You can reuse existing piece of code and apply it to multiple inputs
Formula abstraction in Excel
The one programming tool that has both of these properties is Excel. You might not think about Excel as a programming language, but in many ways, it is one. The following example illustrates how "abstraction" works in excel. I want to do a simple calculation over all rows of a table, so I write the calculation using one concrete value (row) and then "drag it down" to apply the same calculation on the whole table:
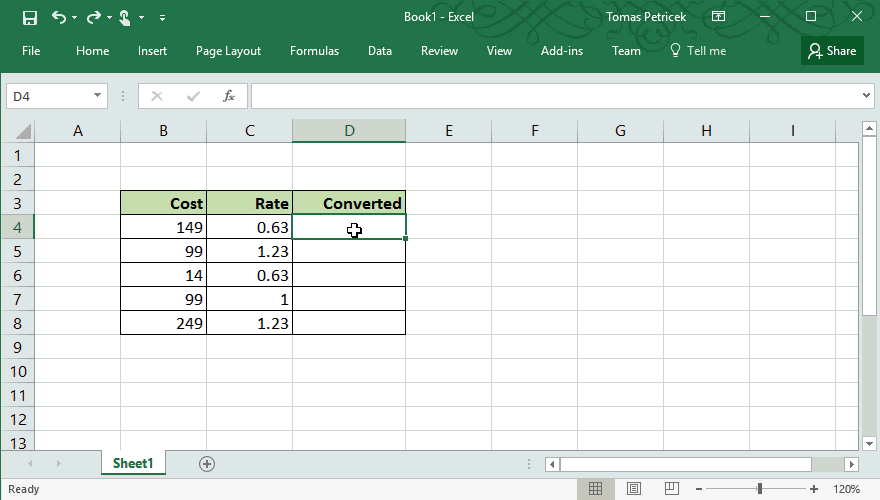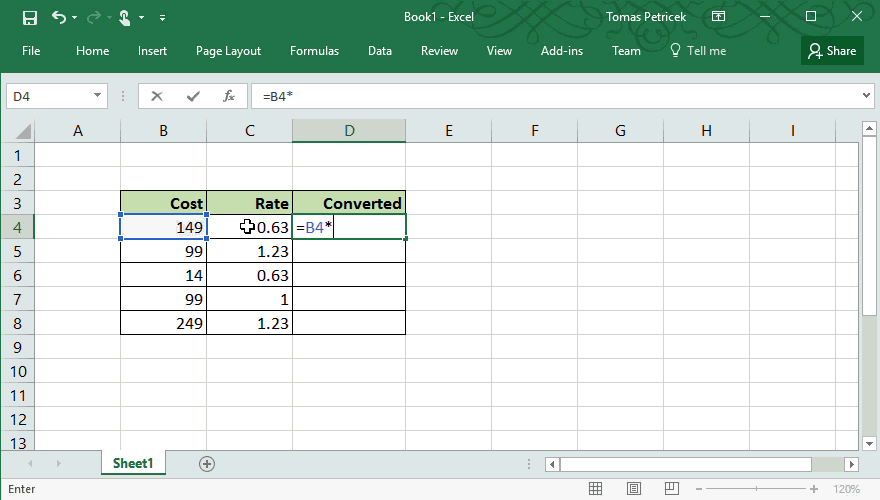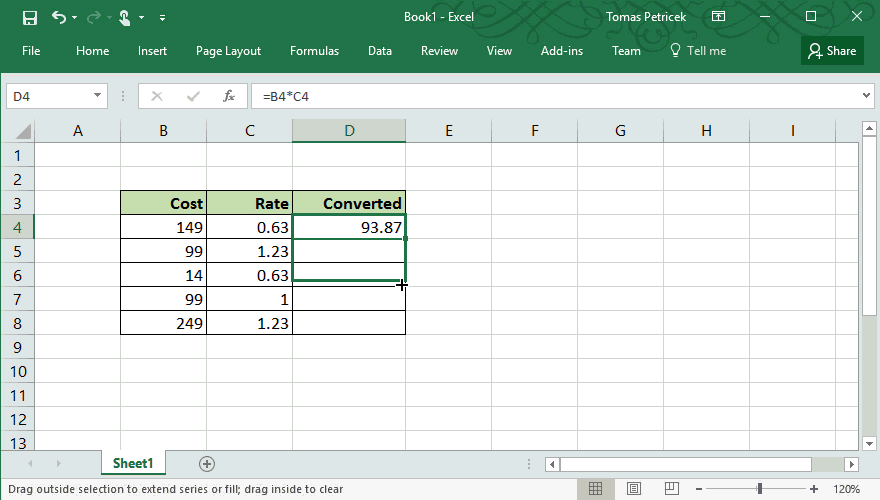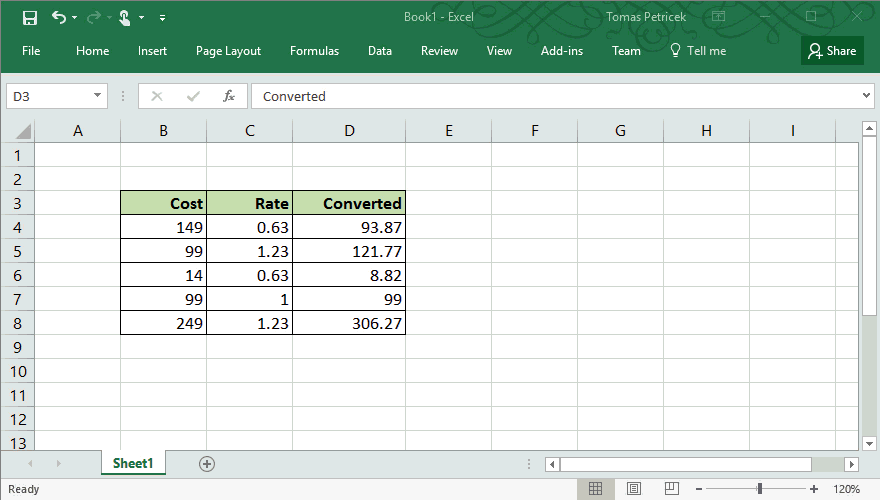
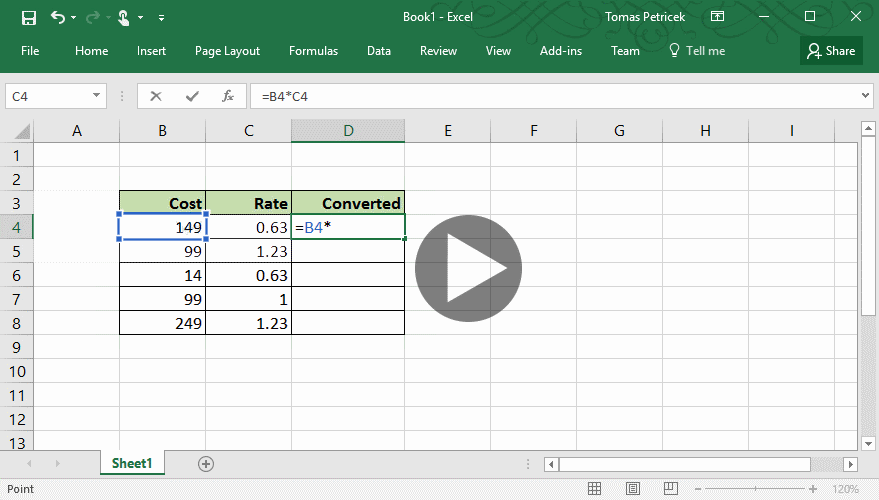
Excel spreadsheets have many issues, but I think the way it lets you apply the same computation on multiple inputs while always working with concrete, relevant values is one thing that it does amazingly well. The Excel feature does have good and bad aspects:
-
The formula in the above example is copied and the reference to the original one is lost, so changing the formula in all rows of the table is error-prone.
-
If you mark the data as table explicitly, Excel will let you refer to columns using the
[@Rate]syntax, which makes the formulas nicer and it also automatically extends the formula over all rows, but this works because spreadsheets are dealing with a fairly simple grid.
From spreadsheets to general-purpose programming
I do not think any programming language achieves quite the same experience as Excel. In the above example, Excel works so nicely because you never work with a name that does not have a concrete value. You can only refer to cells using their index (B4 or C4) and those always have valid values.
-
In the Haskell point-free style, you can write
(sum .) . zipWith (*)with no names (aside from known functions). Here, we are not transforming values, but instead composing a function. There are no concrete values at all. You might like this style for many reasons, but it does not make it possible to get the nice programming tooling that that you get with.when you know the value of an object. -
Language that is perhaps the closest to this idea is Smalltalk with its runtime system where you work with concrete objects (values) and you modify them live. However, in Smalltalk, this works good at the entire-system level, but it is not (as far as I'm aware) used that much when it comes to writing code at message-level.
-
A possibly related design point is LINQ in C# and especially in Visual Basic. In VB, you start your query by specifying data source using
Fromand then select members at the end usingSelect. According to a rumor I've heard, the original proposal was to use SQL-style withSelect .. From .., but there was no way to make the user experience as good as if the names refer to objects of known types. -
Interestingly, visual tools for UI design have similar problem. For example, tools for Silverlight have elaborate methods for generating sample data, so that when you design the UI, you are working with concrete values. But having to explicitly generate fake data does not sound like a reasonable general mechanism to me.
Conclusions
The one principle that makes Excel's dragging of formulas work extremely nicely in contrast to functions in main-stream programming languages like F# and JavaScript is that the Excel abstraction mechanism never produces names without concrete values (or at least types).
Could there be an abstraction mechanism that works nicely in a general-purpose programming language, which has the same property? Even though I have not yet implemented it, I think the answer is yes. I imagine you should be able to write data analytics script using concrete input and then attach name to it and specify which of the inputs can be overridden. This is something that we absolutely need for project like The Gamma, which tries to make data exploration accessible to everyone, but there might be useful lessons for general purpose programming too. To keep an eye on future developments arond The Gamma, follow @thegamma_net on Twitter.
Published: Tuesday, 27 September 2016, 5:53 PM
Author: Tomas Petricek
Typos: Send me a pull request!
Tags: thegamma, research, programming languages