Creating interactive You Draw bar chart with Compost
For a long time, I've been thinking about how to design a data visualization library that would make it easier to compose charts from simple components. On the one hand, there are charting libraries like Google Charts, which offer a long list of pre-defined charts. On the other hand, there are libraries like D3.js, which let you construct any data visualization, but in a very low-level way. There is also Vega, based the idea of grammar of graphics, which is somewhere in between, but requires you to specify charts in a fairly complex language including a huge number of transformations that you need to write in JSON.
In the spirit of functional domain specific languages, I wanted to have a small number of simple but powerful primitives that can be composed by writing code in a normal programming language like F# or JavaScript, rather than using JSON.
My final motivation for working on this was the You Draw It article series by New York Times, which uses interactive charts where the reader first has to make their own guess before seeing the actual data. I wanted to recreate this, but for bar charts, when working on visualizing government spending using The Gamma.
The code for this was somewhat hidden inside The Gamma, but last month, I finally extracted all the functionality into a new stand-alone library Compost.js with simple and clean source code on GitHub and an accompanying paper draft that describes it (PDF).
In this article, I will show how to use Compost.js to implement a "You Draw" bar chart inspired by the NYT article. When loaded, all bars show the average value. You have to drag the bars to positions that you believe represent the actual values. Once you do this, you can click "Show me how I did" and the chart will animate to show the actual data, revealing how good your guess was. Before looking at the code, you can have a look at the resulting interactive chart, showing the top 5 areas from the 2015 UK budget (in % of GDP):
Published: Thursday, 16 July 2020, 11:20 PM
Tags:
functional, functional programming, data science, thegamma, data journalism, visualization
Read the complete article
Data exploration calculus: Capturing the essence of exploratory data scripting
Most real-world programming languages are too complex to be studied using formal methods. For this reason, academics often work with simple theoretical languages instead. The λ-calculus is a simple formal language that is often used for talking about functional languages, the π-calculus is a model of concurrent programming and there is an entire book, A Theory of Objects modelling various object-oriented systems.
Animation from Financial Times article "Why the world's recycling system stopped working".
Those calculi try to capture the most interesting aspect of the programming language. This is function application in functional programming, sending of messages in concurrent programming and object construction with inheritance in object-oriented programming.
Recently, I have been working on programming tools for data exploration. In particular, I'm interested in the kind of programming that journalists need to do when they work with data. A good example is the coding done for the Why the world's recycling system stopped working article by Financial Times, which is available on GitHub.
Although data journalists and other data scientists use regular programming languages like Python, the kind of code they write is very different from the kind of code you need to write when building a library or a web application in Python.
In a paper Foundations of a live data exploration environment that was published in February 2020 in the open access Programming Journal, I wanted to talk about some interesting work that I've been doing on live previews in The Gamma. For this, I needed a small model of my programming language.
In the end the most interesting aspect of the paper is the definition of the data exploration calculus, a small programming language that captures the kind of code that data scientists write to explore data. This looks quite different from, say, a λ-calculus and π-calculus. It should be interesting not only if you're planning to do theoretical programming language research about data scripting, but also because it captures some of the atypical properties of the programs that data scientists write...
Published: Tuesday, 21 April 2020, 3:42 PM
Tags:
academic, research, programming languages, thegamma, data science
Read the complete article
Programming as interaction: A new perspective for programming language research
In May, I joined the School of Computing at the University of Kent as a Lecturer (equivalent of Assistant Professor in some other countries). When applying for the job, I spent a lot of time thinking about how to best explain the kind of research that I would like to do. This blog post is a brief summary of my ideas. I'm interested in way too many things, including philosophy and design and data journalism, but this post will be mainly about programming language research. After all, I'm a member of the Programming Languages and Systems group!

Unlike some of my other posts about programming languages, I won't try to convince you that we should be studying programming languages completely differently this time. Instead, I want to describe one simple trick that will make current programming language research much more interesting!
A lot of programming language papers today talk about programs and program properties. In statically typed programming languages, we can check that a program \(e\) has certain type \(\tau\), which means that, when the program is run, it will only produce values of the type. This is very nice, but it misses a fundamental thing about programming. How was this program \(e\) actually constructed?
When programming, you spend most of your time working with programs that are unfinished. This means that they do not do what they are supposed to be (eventually) doing and, very often, they are not well-typed or even syntactically invalid. However, that does not mean that we can afford to ignore them. In many cases, programmers can even run those programs (using REPL or using a notebook environment). In other words, programming language research should not study programs, but should instead study programming!
I'm also writing this because I'll soon be looking for collaborators and PhD students, so if the ideas in this blog post sound interesting to you or if you've been working on something related, please let me know! You can get in touch at @tomaspetricek or email tomas@tomasp.net.
We'll have funding for PhD students from September 2019 and I'm also working on getting money for a post-doc position. All of these are open ended, so if the blog post made you curious (and you wouldn't mind living in Canterbury or London), definitely reach out!
Published: Monday, 8 October 2018, 1:22 PM
Tags:
academic, research, programming languages, data science
Read the complete article
Getting started with The Gamma just got easier
Over the last year, I have been working on The Gamma project, which aims to make data-driven visualizations more trustworthy and to enable large number of people to build visualizations backed by data. The Gamma makes it possible to create visualizations that are built on trustworthy primary data sources such as the World Bank and you can provide your own data source by writing a REST service.
A great piece of feedback that I got when talking about The Gamma is that this is a nice ultimate goal, but it makes it hard for people to start with The Gamma. If you do not want to use the World Bank data and you're not a developer to write your own REST service, how do you get started?
To make starting with The Gamma easier, the gallery now has a new four-step getting started page where you can upload your data as a CSV file or paste it from Excel spreadsheet and create nice visualizations that let your reader explore other aspects of the data.
Head over to The Gamma Gallery to check it out or continue reading to learn more about creating your first The Gamma visualization...
Published: Wednesday, 14 June 2017, 2:27 PM
Tags:
thegamma, data journalism, data science, research, visualization
Read the complete article
The Gamma dataviz package now available!
There were a lot of rumors recently about the death of facts and even the death of statistics. I believe the core of the problem is that working with facts is quite tedious and the results are often not particularly exciting. Social media made it extremely easy to share your own opinions in an engaging way, but what we are missing is a similarly easy and engaging way to share facts backed by data.

This is, in essence, the motivation for The Gamma project that I've been working on recently. After several experiments, including the visualization of Olympic medalists, I'm now happy to share the first reusable component based on the work that you can try and use in your data visualization projects. If you want to get started:
- Check out thegamma-script package on npm
- Minimal example of thegamma-script in action
- How to use thegamma-script in your projects
The package implements a simple scripting language that anyone can use for writing simple data aggregation and data exploration scripts. The tooling for the scripting language makes it super easy to create and modify existing data analyses. Editor auto-complete offers all available operations and a spreadsheet-inspired editor lets you create scripts without writing code - yet, you still get a transparent and reproducible script as the result.
Published: Wednesday, 25 January 2017, 1:31 PM
Tags:
thegamma, data journalism, data science, research, visualization
Read the complete article
Better F# data science with FsLab and Ionide
At NDC Oslo 2016, I did a talk about some of the recent new F# projects that are making data science with F# even nicer than it used to be. The talk covered a wider range of topics, but one of the nice new thing I showed was the improved F# Interactive in the Ionide plugin for Atom and the integration with FsLab libraries that it provides.
In particular, with the latest version of Ionide for Atom and the latest version of FsLab package, you can run code in F# Interactive and you'll see resulting time series, data frames, matrices, vectors and charts as nicely pretty printed HTML objects, right in the editor. The following shows some of the features (click on it for a bigger version):
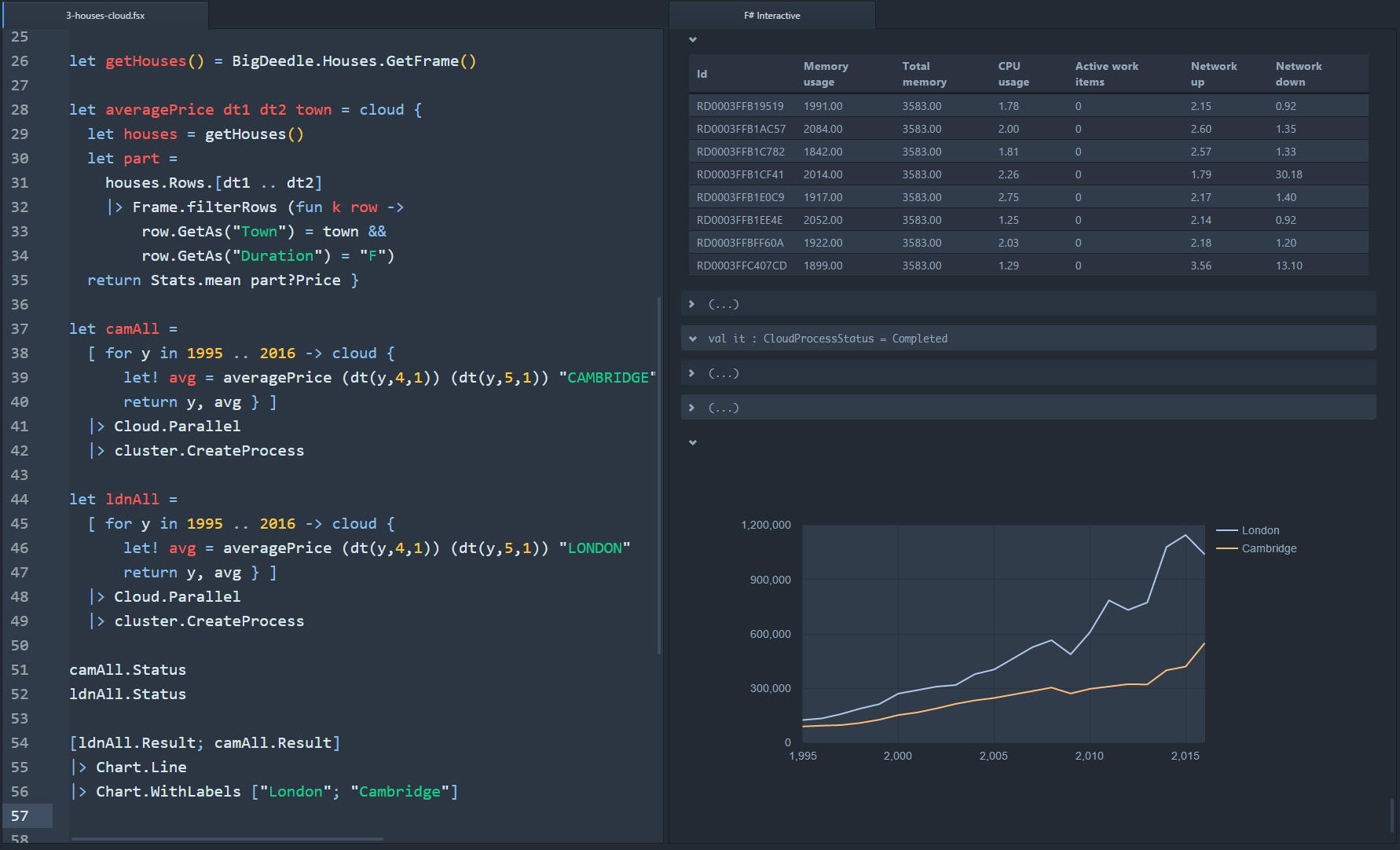
In this post, I'll write about how the new Ionide and FsLab integration works, how you can use it with your own libraries and also about some of the future plans. You can also learn more by getting the FsLab package, or watching the NDC talk..
Published: Wednesday, 6 July 2016, 5:03 PM
Tags:
f#, fslab, data science
Read the complete article
Happy New Year 2016 around the World: Behind the scenes of my #FsAdvent project
Just like last year and the year before, I wanted to participate in the #FsAdvent event, where someone writes a blog post about something they did with F# during December. Thanks to Sergey Tihon for the organization of the English version and the Japanese F# community for coming up with the idea a few years ago!
As my blog post ended up on 31 December, I wanted to do something that would fit well with the theme of ending of 2015 and starting of the new year 2016 and so I decided to write a little interactive web site that tracks the "Happy New Year" tweets live across the globe. This is partly inspired by Happy New Year Tweets from Twitter in 2014, but rather than analyzing data in retrospect, you can watch 2016 come live!
Published: Wednesday, 30 December 2015, 7:09 PM
Tags:
f#, data journalism, thegamma, data science, visualization
Read the complete article
F# + ML |> MVP Summit: Talk recordings, slides and source code

I was fortunate enough to make it to the Microsoft MVP summit this year. I didn't learn anything secret (and even if I did, I wouldn't tell you!) but one thing I did learn is that there is a lot of interest in data science and machine learning both inside Microsoft and in the MVP community. What was less expected and more exciting was that there was also a lot of interest in F#, which is a perfect fit for both of these topics!
When I visited Microsoft back in May to talk about Scalable Machine Learning and Data Science with F# at an internal event, I ended up chatting with the organizer about F# and we agreed that it would be nice to do more on F#, which is how we ended up organizing the F# + ML |> MVP Summit 2015 mini-conference on the Friday after the summit.
Published: Wednesday, 18 November 2015, 3:03 AM
Tags:
f#, fslab, talks, machine learning, data science
Read the complete article
Visualizing interesting world facts with FsLab
In case you missed my recent official FsLab announcement, FsLab is a data-science package for .NET built around F# that makes it easy to get data using type providers, analyze them interactively (with great R integration) and visualize the results. You can find more on on fslab.org, which also has links to some videos and download page with templates and other instructions.
Last time, I mentioned that we are working on integrating FsLab with the XPlot charting library. XPlot is a wonderful F# library built by Taha Hachana that wraps two powerful HTML5 visualization libraries - Google Charts and plot.ly.
I thought I'd see what interesting visualizations I can built with XPlot, so I opened the World Bank type provider to get some data about the world and Euro area, to make the blog post relevant to what is happening in the world today.
Published: Tuesday, 30 June 2015, 5:07 PM
Tags:
f#, fslab, data science, data journalism, thegamma
Read the complete article
Announcing FsLab: Data science package

After over a year of working on FsLab and talking about it at conferences, it is finally time for an official announcement. So, today, I'm excited to announce FsLab - a cross-platform package for doing data science with .NET and Mono.
It is probably not necessary to explain why data science is an important area. We live surrounded by information, but extracting useful knowledge from the vast amounts of data is not an easy task. You have to access data in different formats (JSON-based REST services, XML, CSV files or even HTML tables), you need to deal with missing values, combine and align data from multiple sources and then build visualizations (or reports) to tell the right story.
The goal of FsLab is to make this process easier. FsLab combines the power of F# type providers, the efficiency and robustness of Mono and .NET and the high quality engineering of the open-source ecosystem around F# and C#.
Published: Tuesday, 5 May 2015, 4:55 PM
Tags:
f#, fslab, data science
Read the complete article
FnuPlot: Cross-platform charting with gnuplot
There is a bunch of visualization and charting libraries for F#. Sadly, perhaps the most advanced one, F# Charting, does not work particularly well outside of Windows at the moment. There are also some work-in-progress libraries based on HTML like Foogle Charts and FsPlot, which are cross-platform, but not quite ready yet.
Before Christmas, I got a notification from GitHub about a pull request for a simple gnuplot wrapper that I wrote a long time ago (and which used to be carefully hidden on CodePlex).
The library is incomplete and I don't expect to dedicate too much time to maintaining it, but it works quite nicely for basic charts and so I though I'd add the ProjectScaffold structure, do a few tweaks and make it available as a modern F# project.
Published: Thursday, 15 January 2015, 5:58 PM
Tags:
f#, fslab, data science
Read the complete article
New features and improvements in Deedle v1.0
As Howard Mansell already announced on the BlueMountain Tech blog, we have officially released the "1.0" version of Deedle. In case you have not heard of Deedle yet, it is a .NET library for interactive data analysis and exploration. Deedle works great with both C# and F#. It provides two main data structures: series for working with data and time series and frame for working with collections of series (think CSV files, data tables etc.)
The great thing about Deedle is that it has been becoming a foundational library that makes it possible to integrate a wide range of diverse data-science components. For example, the R type provider works well with Deedle and so does F# Charting. We've been also working on integrating all of these into a single package called FsLab, but more about that next time!
In this blog post, I'll have a quick look at a couple of new features in Deedle (and corresponding R type provider release). Howard's announcement has a more detailed list, but I just want to give a couple of examples and briefly comment on performance improvements we did.
Published: Tuesday, 27 May 2014, 4:41 PM
Tags:
f#, deedle, data science
Read the complete article