Asynchronous Programming in C# using Iterators
In this article we will look how to write programs that perform asynchronous operations without
the typical inversion of control. To briefly introduce what I mean by 'asynchronous' and
'inversion of control' - asynchronous refers to programs that perform some long running operations
that don't necessary block a calling thread, for example accessing the network, calling web services
or performing any other I/O operation in general. The inversion of control refers to the code structure
that you have to use when writing a code that explicitly passes a C# delegate as a callback to the
asynchronous method (typically called BeginSomething in .NET). The asynchronous method
calls the delegate when the operation completes, which reverses the way you write the code - instead of
encoding the control flow using typical language constructs (e.g. while loop) you have to
use global variables and write your own control mechanism.
The funny thing about this article is that it could have been written at least 3 years ago when a beta version of Visual Studio 2005 and C# 2.0 became first available, but it is using iterators in a slightly bizarre way, so it is not easy to realize that this is possible. Actually, I will use some C# 3.0 methods in the article as well, but only extension methods and mainly just to keep the code nicer. As with my earlier article about building LINQ queries at runtime, I realized that it can be done in C# when I was playing with the F# solution (called F# Asynchronous Workflows), where this approach is very natural, so I will shortly mention the F# implementation as well.
Introduction
Let's first look how we can write a code that uses asynchronous operations using the usual techniques in C#. I'll shortly demonstrate both synchronous version, which is easy to write, and asynchronous version, which is efficient, because it doesn't block the thread (and in fact it should be used in all situations, because blocking a thread is very bad practice). After looking at C# solutions we'll look (very briefly) at F# Asynchronous Workflows [1, 2, 3], which inspired the C# solution presented later in this article. The F# Asynchronous Workflows allow writing asynchronous code in a same way as you would write the synchronous version, but are executed in a non-blocking way.
Let's start with a very simple example, which uses HttpWebRequest to download a
page from the web and prints the downloaded HTML in a console window. The only asynchronous
operation that we will use in the sample code is GetResponse, which has an asynchronous
alternative BeginGetResponse. In the samples below I'll use StreamReader
to get the HTML of the response which should be also done asynchronously, but unfortunately there
is no BeginReadToEnd method which we could easily use (I'll address this problem later
in the article). The synchronous (blocking) version of the code looks like this:
static void DownloadSync(string url)
{
WebRequest req = HttpWebRequest.Create(url);
WebResponse response = req.GetResponse();
Stream resp = response.Result.GetResponseStream();
using (var sr = new StreamReader(resp))
Console.WriteLine(sr.ReadToEnd());
}
The code first creates WebRequest and then uses its GetResponse method
to get the response. This call connects to the server, which can take a long time, so it is a good
idea to use asynchronous BeginGetResponse method instead. The next example demonstrates
how the C# code using this method looks like:
static void DownloadAsync(string url)
{
WebRequest req = HttpWebRequest.Create(url);
req.BeginGetResponse((ar) => {
WebResponse response = req.EndGetResponse(ar);
Stream resp = response.GetResponseStream();
using (var sr = new StreamReader(resp))
Console.WriteLine(sr.ReadToEnd());
}, null);
}
Here, we're calling BeginGetResponse, which takes a delegate as an argument - the code
uses C# 3.0 anonymous functions (and you could also use C# 2.0 anonymous delegates), to create the delegate
without declaring a new method. Of course, in this simple case, the code doesn't look dramatically worse -
it has only 2 additional lines and it adds some indentation, but try nesting 4 asynchronous calls and the
code will become very ugly. What's even worse, sometimes you may need to use constructs like while
loop which cannot be used in this programming style and instead you have to declare a few helper methods and
some global fields to keep the current state.
In F#, you can use a feature called Asynchronous Workflows to overcome these difficulties. This feature is already in details described in articles by Don Syme [1] and Robert Pickering [2, 3], so I will not go into details here. The previous C# code written in F# would look like following:
let DownloadAsyncFSharp(url:string) =
async
{ let req = WebRequest.Create(url)
let! rsp = req.GetResponseAsync()
use stream = rsp.GetResponseStream()
use sr = new StreamReader(stream)
do Console.WriteLine(sr.ReadToEnd()) }
The important thing about this code is that it is written in a same way as synchronous code, but
it executes asynchronously - it is actually a more general language feature, so the specific asynchronous
behavior is controlled by the async value which introduces the code block wrapped in curly braces.
You can see that the call to GetResponseAsync (which is an extension method added by the F#
library) is done using let!, which is a place where the non-standard call is performed in any
code block in curly braces (these are called computation expressions in F#, and for those familiar with Haskell
are essentially the same thing as monads).
When the code starts executing it runs on some thread (let's say on a thread from .NET thread pool) until it
gets to a GetResponseAsync. This method returns a value which represents the operation, which
should be performed (in this case the fact that BeginGetResponse should be called) and gives this
to some function associated with the async value. This function takes this value (in F# it has a
type Async<WebResponse>) and a delegate that should be called when the operation completes -
note that here the F# compiler automatically splits the code into a part that is executed before the call
done using let! and a part that will be executed after as a continuation and this second
part is given as a delegate to some special function which performs the call asynchronously. The following
code shows graphically how the code is divided into two parts - Here, the green part is first block of code
that will be called and the violet block of code is a part that is compiled into a delegate (a continuation)
that is given as an argument to the special function associated with the async value:
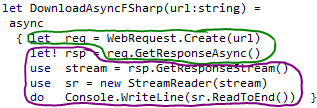
So, once this special function is called it starts the asynchronous call and gives it a delegate that represents the rest of the computation expression. The special function then returns (without waiting for the result), and the thread is returned to a thread pool. Once the asynchronous operation completes, another thread is picked from a thread pool and the rest of the computation expression is executed on this thread.
The interesting thing about the execution of the code is that let! creates a "hole" in the function
where the execution can be transferred to another thread. In the graphical representation the "hole" is indeed
in a place where the function is divided into green and violet parts. In the next part of the article, you'll see that
yield return introduced in C# 2.0 lets us create similar "holes" in C# methods and that these
can be used to emulate F# Asynchronous Workflows in C# (with relatively little loose of elegance).
Asynchronous Workflows in C#
Now, let's look how the same thing can be written in C# using iterators. All the following examples are using
a few library functions and types that I implemented and that can be downloaded at the end of the article. We will
write any asynchronous method as a method which returns IEnumerable<IAsync>, which allows us to
use yield return in the body of the method. When we need to call primitive asynchronous method
(like GetResponseAsync, which is an extension method added by my library to a WebRequest
type) we will get a result of type Async<...>, which represents the asynchronous operation and
has to be returned using yield return to force its execution. This causes the operation to be performed
asynchronously and subsequently, the rest of the method will be executed (possibly on a different thread) and the
return value will become available as a property called Result of the Async<...> value.
static IEnumerable<IAsync> DownloadAsync(string url)
{
WebRequest req = HttpWebRequest.Create(url);
Async<WebResponse> response = req.GetResponseAsync();
yield return response;
Stream resp = response.Result.GetResponseStream();
Async<string> html = resp.ReadToEndAsync().ExecuteAsync<string>();
yield return html;
Console.WriteLine(html.Result);
}
In this example we declared a method with the return type mentioned above, which first creates web request
(using HttpWebRequest.Create) and then calls extension method GetResponseAsync, which
returns a value of type Async<WebResponse>. This value doesn't yet contain a response and
instead just represents a computation that can be executed asynchronously. Later, this value is returned using
yield return, which transfers the control to some code that executes the asynchronous method in
a special way (we will shortly see how the DownloadAsync method can be invoked) and this code
executes the operation asynchronously, which means that the calling thread can continue with executing other
computations (when the method was just spawned without waiting for the result), or is returned to a thread pool.
Later in the code, we use the ReadToEndAsync extension method which is again defined as an extension
method in my library - this method replaces the use of synchronous StreamReader with an asynchronous
version, which is an issue that I mentioned in the introduction. This method itself is defined as asynchronous using
the described technique and has a type IEnumerable<IAsync>. In this example, we want to execute
it asynchronously as part of a larger asynchronous computation, but our code can't continue before the ReadToEndAsync
method completes. This means that we need to call the method in a way in which it returns a value of type
Async<...>, which is how we represent waiting for a result of an asynchronous operation. Luckily,
there is ExecuteAsync extension method, which can be used to do this (this is an important method
that I will discuss in a deeper detail later).
Let's now look at the final part of the example - when executing asynchronous operations, we can either spawn it and don't wait for the result, which is sometimes useful, but more usual situation is when we need to perform multiple asynchronous operations in parallel and wait until all of them complete. This is also a situation where the asynchronicity is important, because we don't want to run every operation on a single thread to get better parallelism and this approach can be also used for tasks that mix CPU-intensive and I/O intensive operations. The following example demonstrates the second case - executing several downloads in parallel:
static IEnumerable<IAsync> DownloadAll()
{
// Create an asynchronous computation by running a
// bunch of asynchronous workflows in parallel
Async<Unit> methods = Async.Parallel(
DownloadAsync("http://www.microsoft.com"),
DownloadAsync("http://www.google.com"),
DownloadAsync("http://www.apple.com"),
DownloadAsync("http://www.novell.com"));
yield return methods;
Console.WriteLine("All pages downloaded!");
}
// Run the 'DownloadAll' method and wait until it completes
static void Asynchronous()
{
DownloadAll().ExecuteAndWait();
}
In the first method (DownloadAll) we're again implementing a new asynchronous method and the only thing that
the method does is that it uses Async.Parallel to combine several primitive asynchronous operations into
one asynchronous operation (represented using our well known Async<...> type). Since the methods just
execute and don't return any result, we're using a type called Unit, which is a type representing C# void,
but with adding some flexibility - the void type can't be used in a way we need it here, so the result of
the asynchronous operation is not interesting, we however still need to call yield return to force execution
of the operation. Finally, in the second method we use very simple extension method called ExecuteAndWait, which
as you would expect, executes asynchronous method that we defined (i.e. a method with return type IEnumerable<IAsync>)
and waits until the operation completes - even in this trivial example the operation performs several downloads in parallel,
so there is still an advantage in executing the operation asynchronously.
How Does it Work?
Before looking at some more examples, I'll try to comment a little bit how the code in C# actually executes.
First of all, why is the code using IEnumerable<IAsync> when there is no iteration over collections
(and also no matching foreach loop). The reason is that the C# 2.0 compiler compiles the code of iterator in
a way that allows us calling the MoveNext method of the generated iterator from another object and
the code in the iterator executes lazily just by moving to the next yield return during every call to the
MoveNext method (slightly more technical explanation that you can safely skip is that the code is compiled into
a state machine where every yield return represents a state and MoveNext performs a state transition).
Once we have an iterator written like this, the underlying library which manages invocation of these methods can start executing
the code in the method (by calling MoveNext) and the execution will stop after a value is returned from the
method using yield return. This then returns an object (usually Async<...>, but in general any
object implementing IAsync interface), which represents the asynchronous operation. This basically means that
the object just knows what .NET BeginSomething method it should execute. Once this object is returned
the underlying library asks the object to execute the BeginSomething method and tells it that when
the method completes it should again call MoveNext to proceed to another primitive asynchronous operation
used in our asynchronous method.
In the previous example we have used the ExecuteAndWait method to run the asynchronous computation -
when you look at the code, you can see that asynchronous methods have return type IEnumerable<IAsync>,
which means that this is a type that we're using for representing asynchronous computations. When you call an
asynchronous method the code immediately returns this type without stepping into the user code in the method,
because C# 2.0 iterators are executed lazilly, so we just get an object that represents our computation and that can
be further executed by the underlying library. The type is just an interface (IEnumerable<IAsync>),
so we're using a new C# 3.0 feature here, called extension methods, which allows us to call static method
ExecuteAndWait taking this interface as a first argument using a much nicer dot-notation. This method
then starts executing the code asynchronously, but it blocks the calling thread until the operation completes. This
makes sense only when the method is executing some operations in parallel, otherwise there wouldn't be any benefit from
writing the method as asynchronous, however in more real-world situations you'll typically use similar extension
method called Execute, which just spawns the computation on a thread pool thread and immediately returns,
so the caller thread can be used for other tasks. Finally, there is also ExecuteAsync extension
method, which is useful when calling asynchronous method from another asynchronous method and which will be discussed
further.
Calling Async Methods
The last topic that I want to discuss in this introduction is composability of the solution that I'm discussing in this article. This is indeed one of the most important aspects of any library, because writing a single asynchronous method without the ability to easily call other asynchronous method wouldn't help us write clear code very much. If you have previous experiences with writing asynchronous code then you can tell that composability is a problem with the current solutions. As I mentioned in the introduction, the problem is inversion of control which makes it very hard to encode any control flow in the code.
In the example earlier I shortly mentioned the ReadToEndAsync method, which reads all data from a
stream asynchronously and uses a StreamReader to convert the data to string, without blocking the thread, which
is a default StreamReader behavior. The method is actually implemented in the library, but it is using only
the features that I already described, so you can implement and call similar methods from your code as well. As any
asynchronous method in this article, the method has return type IEnumerable<IAsync> and the implementation
looks like following:
public static IEnumerable<IAsync> ReadToEndAsync(this Stream stream)
{
MemoryStream ms = new MemoryStream();
// Read bytes from the stream asynchronously and copy
// them to a memory stream until the Read returns 0 bytes.
int read = -1;
while (read != 0)
{
byte[] buffer = new byte[1024];
Async<int> count = stream.ReadAsync(buffer, 0, 1024);
yield return count;
ms.Write(buffer, 0, count.Result);
read = count.Result;
}
// Seek to the beginning of the stream and read string
ms.Seek(0, SeekOrigin.Begin);
string s = new StreamReader(ms).ReadToEnd();
// Return the read string using 'Result'
yield return new Result<string>(s);
}
The first interesting thing about this method is that it uses quite complex control structure - a while
loop to implement the asynchronous method. Indeed, when the code is executing asynchronously, each iteration of the loop
can be executed on another thread, because there is a yield return inside the loop, which represents
an asynchronous operation, which is executed in a non-blocking way and after that the rest of the method is started on
a new thread pool thread. Technically speaking, we're leveraging of the tricks that the C# 2.0 compiler does to when
it compiles a code that uses while loop to an iterator that can be invoked step-by-step using the
MoveNext method.
The second interesting aspect of this method is that it returns a string as a result - unfortunately, this is not
as easy as it should be. The problem here is that the return type of the method has to be IEnumerable<IAsync>,
meaning that the signature of the method doesn't include the return type. Also, we can't use return statement,
because the method is implemented as a C# 2.0 iterator, so instead we use yield return and a special class
called Result, which allows us to return a result from an asynchronous method. The underlying framework knows
this type, so we'll be able to call the method and access the result later.
The method ReadToEndAsync is declared as an extension method (notice that there is a this
keyword before the first parameter), which means that it can be invoked using dot-notation on any stream. The following
code (taken from an asynchronous method demonstrated earlier) shows how this call can be performed:
Stream resp = response.Result.GetResponseStream();
Async<string> html = resp.ReadToEndAsync().ExecuteAsync<string>();
yield return html;
Console.WriteLine(html.Result);
The purpose of the previous code snippet is to demonstrate how asynchronous methods (written as methods with return type
IEnumerbale<IAsync> can be called from another similarly declared asynchronous method. You can see that
in this sample we're calling ReadToEndAsync method declared earlier and to call it we're using extension method
ExecuteAsync, which produces a value of type Async<...>, which is a type that we've been
using during the whole article to represent primitive asynchronous operation. In this case, we know that the method
returns a string, so we give it a string as a type argument, to specify the return type. Later, the primitive
asynchronous operation is evaluated using yield return and the result can be accessed using the Result
property.
Summary
In this article we looked at very interesting way for implementing asynchronous operations in C# using iterators, which is based on the approach used in F# Asynchronous Workflows (actually, this is based on a thing called continuation monad from languages like Haskell, but I didn't want to make the code too scary!). The key point of this article is to demonstrate that C# iterators can be used for implementing asynchronous operations without explicitly using delegates and event-driven programming style, which makes it very difficult to encode the control flow of the code. I also implemented several methods that provide access to basic .NET functionality in this way, so you can start playing with the library if you're writing asynchronous code. As far as I'm concerned the performance of the code should be similar as a performance of the code written explicitly using delegates, so the only possible problem with the code is that returning a result from a method has to be done without explicitly mentioning the return type in the method signature as discussed in the article. On the other side the benefits of writing a code without inversion of control are obvious and the examples that we implemented in this article demonstrate them very well.
Finally, I should mention that Jeffrey Richter's article in MSDN Magazine November 2007 issue [4] mentions some very similar concepts to the solution described in this article. He promises more details for the next issue, so I'm looking forward to reading about and learning from a similar project. My implementation is not related to Jeffreys project and is instead taking many ideas from F# Asynchronous Workflows, where asynchronous code can be written more elegantly without "misusing" language features, which I to some point did in this article.
Downloads & References
- Download the Library and Samples (33 kB)
- The source code is also available from LinqExtensions project at CodePlex
- [1] Introducing F# Asynchronous Workflows - Don Syme's WebLog on F# and Other Research Projects
- [2] Concurrency in F# – Part I – The Asynchronous Workflow - Robert Pickering's Strange Blog
- [3] Concurrency in F# - Understanding how Asynchronous Workflows Work - Robert Pickering's Strange Blog
- [4] Articles by Jeffrey Richter - MSDN Magazine
Published: Thursday, 15 November 2007, 3:08 AM
Author: Tomas Petricek
Typos: Send me a pull request!
Tags: c#, parallel, asynchronous