What can programming language research learn from the philosophy of science?
As someone doing programming language research, I find it really interesting to think about how programming language research is done, how it has been done in the past and how it should be done. This kind of questions are usually asked by philosophy of science, but only a few people have discussed this in the context of computing (or even programming languages).
So, my starting point was to look at the classic works in the general philosophy of science and see which of these could tell us something about programming languages.
I wrote an article about some of these ideas and presented it last week at the second symposium on History and Philosophy of Programming. For me, it was amazing to talk with interesting people working on so many great related ideas! Anyway, now that the paper has been published and I did a talk, I should also share it on my blog:
- What can Programming Language Research Learn from the Philosophy of Science?
- Fairly minimalistic slides from my talk at the symposium
One feedback that I got when I submitted the paper to Onward! Essays last year was that the paper uses a lot of philosophy of science terminology. This was partly the point of the paper, but the feedback inspired me to write a more readable overview in a form of blog post. So, if you want to get a quick peek at some of the ideas, you can also read this short blog (and then perhaps go back to the paper)!
Where does philosophy of science start from?
One of the goals of philosophy of science is to try to understand how scientists work, and, possibly, try to find the borderline between good and bad science. Compared to more established sciences like biology or physics, computing is a fairly new discipline. So, it is not surprising that there is not a large body of work done in philosophy of computing or, more specifically, programming languages.
However, I believe that we can still learn a lot from philosophy of science in general. Much of the classical work in the area uses physics as an example of successful science:

The undoubted success of physics (...) is to be attributed to the application of (...) 'the scientific method'. If (other disciplines) are to emulate the success of physics then that is to be achieved by (understanding and applying this method).
Alan Chalmers
What Is This Thing Called Science? (1999)
Now, physics might not be the best model for computing or programming language research, but I think it is a good starting point. If not for other reasons then because there is a large number of interesting works arising from it. So, I'll often refer to physics in this article - but I think we could also learn a lot by looking at engineering, mathematics or even economics.
Is programming language research a science?
We could get stuck on the question whether programming language research is a science for a long time. First of all, there is no single clear definition of what is science. A more interesting question is - from what point of view is programming language research a science? Let me start with perhaps the best known theory.
Karl Popper's falsificationism
Given a theory, finding whether the theory is true is a hard problem. Even if we verify it using an experiment, we can never test the theory in all cases. Karl Popper came up with a great way to avoid this problem:

(I shall) admit a system as scientific only if it is capable of being tested by experience. These considerations suggest that not the verifiability but the falsifiability of a system is to be taken as a criterion of demarcation.
Karl Popper
The Logic of Scientific Discovery (1934)
According to Popper, a theory if scientific if it can be falsified. This view is certainly more applicable to physics where we can observe the world and build theories that predict how it works.
Is this applicable to programming language research? This is a bit tricky - we do not often make falsifiable claims. And if I claimed that using a language X leads to fewer bugs, it can be falsified immediately - just write a really buggy program in the language X!
Falsificationism can certainly be useful in some areas of programming language research. For example, if you are doing work on performance, then you should make well qualified falsifiable statements - for example, in certain conditions, one implementation is faster than another.
But outside of a fairly narrow area of performance, I don't think that falsificationism offers a useful perspective. However, there is another interesting view that we can explore...
Ian Hacking's new experimentalism
Popper emphasizes scientific theories and attributes somewhat second-class role to experiments. The only purpose of experiments is to falsify theories. According to Hacking, experimentation is much more valuable and important part of science:

Experimentation has a life of its own, interacting with speculation, calculation, model building, invention and technology in numerous ways.
Ian Hacking
Representing and Intervening (1983)
I think this is an excellent point that applies to a lot of work in programming language research. Very often, people start creating a language or software project just by experimenting. They write some code, see how the language works and see whether it solves some problems that are difficult to solve otherwise. The experimentation often changes what you actually end up doing - so there is no clear theory preceding the experimentation.
In Hacking's view, experimentation is an important part of science. However, he also says that experiments are often treated as second-class compared to theories. I think this is also the case for some of programming language research. It is often the case that, in order to publish some interesting work (done in the form of experiment), you need to create a theory (a formal model) and then talk about the formal model. And during this process, interesting aspects of the experiment can easily get lost.
Another interesting point by Hacking is that experiments can be theory-independent. Now, if we see programming languages as theories, this has an interesting implication. It says that we could do experiments (write programs) and talk about them in a way that does not depend on the programming language. This means that we could also compare different programming languages. This is something that PL researchers do not do, because there is no "scientific" way for this. My suggestion, which I'll get back to later, is to use case studies.
Structures of programming language research
Another perspective that we can use when looking at science is to look at the history and look if there is some structure. Does the science follow some patterns? And can we learn from them?
Perhaps the most famous author who uses this approach is Thomas Kuhn with his idea of scientific revolutions. John Tarbox suggested to me that the change from analog to digital computers might be an example of such revolution and I think this is a pretty interesting idea. But for programming languages, I do not think that we have enough historical material yet, so I'll skip this topic for now. But there are other interesting views.
Imre Laktos's research programmes
The basic idea of Imre Lakatos is that there are multiple groups of scientists pursuing different research programmes. They do not need to be aware of this and we can only find out in retrospect. Each research programme has its core with assumptions that the scientists take as granted and do not modify. Then there are peripheral assumptions which is where science is done:

Scientists can seek to solve problems by modifying the more peripheral assumptions (...). (They) will be contributing to the development of the same research program however different their attempts (...).
Imre Lakatos
(as quoted by A. Chalmers)
I think this is a really interesting idea. For example, we can take pure functional programming as an example of such research programme. Everyone doing work in the area of pure functional programming will share some common assumptions that they do not want to modify - for example, using immutable state, avoiding side-effects etc. However, this still leaves a lot of peripheral assumptions where different language aspects can be developed.
Another interesting point is how problems are approached. Lakatos says that when a scientist faces an experimental failure, they always seek to modify peripheral assumptions. What does this mean for programming languages? Let's consider the purely functional programming example again. If it becomes difficult to implement some algorithm efficiently, members of the research programme never attribute this to the core assumptions (like the inability to use mutation), but always blame peripheral assumptions (e.g. insufficient compiler optimizations).
This makes misunderstandings really easy - if someone who has different sets of core assumptions looks at the problem, they may find the solution silly (e.g. I may wonder why not just use mutable arrays?)
Paul Feyerabend's theoretical anarchism
We may find some structure in some parts of history, but finding a general pattern that applies to everything is hardly going to work. Paul Fyerabend summarises this nicely as follows:

To those who look at the rich material provided by history (...) it will become clear that there is only one principle that can be defended under all circumstances and in all stages of human development.
It is the principle: anything goes.
Paul Feyerabend
Against Method (1975)
Paul Feyrabend also says that science is far more "sloppy" than its methodological image. So, not only there is no nice structure, but science is also not rational - it is done by humans who often make irrational decisions.
I think every reader can find their favorite examples from the programming language world here. However, what we can learn from Feyerabend is to acknowledge this fact and do not be afraid to look outside of the restricted scientific region.
For example, more theoretical programming language research often ignores the industry, because the work done in the industry is not doing "good science". But this means that we are completely ignoring a fair amount of possibly interesting ideas!
I should say that Feyerabend does not say that there should be no order. He just says that history does not give us any guidance on which methods are the right scientific methods - and so we should not use it to overly constrain what is viewed as "scientific". According to Feyerabend (and I fully agree here), his theoretical anarchism is also more humanitarian and more likely to encourage progress than the law-and-order alternatives.
Learning from philosophy of science
So far, my main focus has been on looking at the existing classical works in philosophy of science and trying to re-interpret some of them in the context of programming language research. I believe this is an interesting and useful thing to do. It can teach us something about our field and perhaps give us some hints how to do our work better.
In this last section, I'll make three such suggestions.
A case for plurality
My first idea is inspired by Lakatos and Feyerabend. They both agree that scientists hold multiple core assumptions (in case of research programmes) or inconsistent theories. To quote Feyerabend:
The methodological unit to which we must refer (is a) set of partly overlapping, (...) but mutually inconsistent theories.
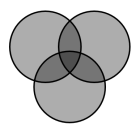
I think this is an important point. It means that judging other people's work may be quite hard. If I hold a different set of core assumptions than the author of the work I'm reading, then I can easily dismiss it as completely wrong - but that is because it modifies some assumptions that I treat as core while the author treats them as peripheral.
So, we end up accepting only work that stays in a completely safe zone. To see what I mean, look at the diagram above. If three people with three sets of core assumptions judge some work, the work can only modify assumptions that are outside of the union of the three sets. As a result, we make it hard to publish work that does an interesting more fundamental change.
For example, in the early days, purely functional programming languages had no good way of handling input and output. As such, any research in this area could be dismissed simply by saying: "This is rubbish, how do you print stuff?" Luckily, this did not happen, because FP was given enough time to develop auxiliary techniques for handling I/O like linear logics and monads. But one can easily imagine something like this happening to an interesting piece of work.
A case for inexactness
The second thing that we can learn from the history is that new theories often start as imperfect. This has been said by both Kuhn (about paradigms) and Lakatos (about research programmes). Paul Feyerabend makes the same point:
Logically perfect versions usually arrive long after imperfect versions have enriched science.
(Requiring exactness) deflects the investigation into the narrow channels of things already understood and the possibility of fundamental conceptual discovery (is) reduced.
I think many interesting ideas in programming language research also start as imperfect. I'm sure some people would disagree, but I find important but imperfect research much more valuable than perfect and unimportant work. Feyerabend finds many examples of important scientific contributions that started as imperfect.
Now, we do not have to go as far as Feyerabend and require no order at all. However, I think that accepting certain level of inexactness in the early stages of interesting research is perfectly acceptable (and I'm happy to see events like Onward! in this direction, but I think there is a lot more that could be done).
A case for experiments
The last point that I'd like to make goes back to Ian Hacking and his focus on experiments. First of all, he says that experiments are (and should be treated) as first-class part of science, even if they do not confirm or falsify any theory:
One can conduct an experiment simply out of curiosity to see what will happen.
I think this is often how programming language research is done, but sadly, we have no good way of presenting experiments in themselves. In the best case, you can submit source code with an academic paper as an auxiliary material - but this is just continuation of the second-class treatment of experiments:
We find prejudices in favor of theory, as far back as there is institutionalized science.
So, I think we need to find a way of presenting and talking about experimentation. Ideally, this should be theory-independent - or, in terms of programming language research, it should avoid talking about the formal models and details and focus on some interesting and telling example.
In my opinion, one way to do this would be in the form of case studies. When I create something interesting, I can describe how it has been done (perhaps even without all the technical details) and talk about the properties of the solution, rather than the theory behind it. I'm not sure how exactly this should look, but something like The Yampa Arcade seems close in some aspects.
Another important aspect of theory-independent experiments, or case studies, is that it would let us compare different programming languages. Perhaps not in a formal way, but at least in some way. When you see an implementation of similar problem in different languages, it can tell you something interesting (see "The dependency diagrams" section). This is not something you can learn from "toy" examples.
Why history and philosophy matters
To conclude, let me go back to the main idea of this article and my more detailed paper on this topic. I think that looking at the history and philosophy of programming language research (or computing in general) is a really important thing.
If we want to learn how to do good science, we first need to understand what does this actually mean. As a computer scientist, I could just leave these questions to philosophers and historians and do not worry. But I think that trying to understand what we do and how we can do it better is a fundamental part of good science.
I finished this article with three specific ideas how we could improve the practice of programming language research. I'm sure many people will disagree with some of my points, but that's perfectly fine. My main goal is to show that there are interesting things we can learn and infer.
Also, I do not claim that physics is the best model of good science for computing or programming language research. On the theoretical side, we can probably learn a lot from philosophy of mathematics. On the practical side, engineering gives another important view. Somewhere in between, economics is also interestingly related in that it partly constructs the world that it studies.
So, there is a lot more that could be done! If you want to read the full details of what I briefly presented here, then have a look at the longer published version and check out the History and Philosophy of Computing web.
Published: Thursday, 10 April 2014, 6:16 PM
Author: Tomas Petricek
Typos: Send me a pull request!
Tags: research, philosophy