Choose Your Own Adventure Calculus
The rule of three suggests that if you encounter the same pattern for the third time in your code, you should refactor it into a reusable abstraction. The same thing applies in programming language theory. When you find that you are doing the same thing for the third time, it is probably a good idea to stop and think - is there a general pattern?

Figure 1. Auto-completion list showing possible operations in The Gamma
In my PhD thesis on context-aware computations, I did exactly this. When we realised that liveness analysis, resource tracking and checking of data-flow computations all require type system with similar structure, we came up with the idea of coeffects, which is an abstraction that can capture all three (and so, you only need to add one mechanism for tracking context into your language).
Recently, the same thing happened to me again. A lot of my work has been around interaction with programming systems. I am interested in looking not just at the programming languages, but also the stateful, interactive systems they are part of - and how programs are created through interactive editor tools, gradually revised in notebook systems or how proofs are created in interactive proof assistants. And interestingly, in three recent collaborations around those ideas, we ended up finding a very similar pattern.
In multiple different systems, we encountered a pattern where the programming system iteratively offers the user (programmer, data scientist, proof theoretician) a choice of options that the user can choose from to construct or refine their program (see Figure 1). In all systems, the user can also edit the code in other ways, but a lot (sometimes everything!) can be done just by choosing options.
I now have three examples, so it is time to describe the general pattern. Earlier, we called this (jokingly) dot-driven development, (seriously) AI assistants and (foolishly) iterative prompting. For the lack of a better name, I will refer to the abstraction as the choose-your-own-adventure calculus.
Published: Sunday, 2 February 2025, 2:52 PM
Tags:
research, academic, programming languages, thegamma, type providers
Read the complete article
What can routers at Centre Pompidou teach us about software evolution?
Back in June, I was in Paris for the NewCrafts conference to talk about the growing opacity of software systems. This was fun, partly because NewCrafts is a fantastic conference (you can already get your tickets for 2024!) and also partly because my talk (arguing against many established "good engineering" practices) was in many ways arguing for the exact opposite than one of the keynotes, leading to many interesting conversations.
While in Paris, I also visited the famous Centre Pompidou. Perhaps to the dismay of many modern art lovers, I spent a lot of time staring at the ceiling looking for routers.



Spot the routers at Centre Pompidou!
Published: Thursday, 7 December 2023, 6:30 PM
Tags:
research, academic, programming languages, design, architecture
Read the complete article
Where programs live? Vague spaces and software systems
Architecture and urban planning have been a useful source of ideas for thinking about programming. I have written various blog posts and a paper Programming as Architecture, Design, and Urban Planning that argue why and explore some of those ideas. Like urban planning and architecture, the design of any interesting software system deals with complex problems that can rarely be analysed in full and with structures that will continue to evolve in unexpected ways after they are created.
My most recent reading on cities was a book The City Inside Out (Czech only, unfortunately) that explore places referred to as terrain vague. This term refers to unused and abandoned spaces that have lost their purpose or do not have a clear use, but are used in various ways nevertheless. For various historical reasons, there seem to be quite a few of such places in Prague (Figure 1) and, more generally, Central European cities, which is the focus of the book.
The book is an interesting inspiration for thinking about programming in many ways. It uses an inter-disciplinary approach ranging from history and philosophy to archaeobotany, which is much needed for thinking about programming too. (Not archeobotany, but inter-disciplinary thinking certainly!) More specifically, it makes you think about the concept of a space in which cities and programs exist, how the spaces inhabited by the two differ, what would it look like if they were different and what structures get created in those spaces as a result of social and technical forces.

Figure 1. Nákladové nádraží (freight railway station) Žižkov - an example of a large
space in Prague that no longer serves its original purpose (photo source)
Published: Friday, 10 February 2023, 11:44 PM
Tags:
research, academic, programming languages, design, architecture
Read the complete article
The Timeless Way of Programming

Figure 1. The Timeless Way of Building - Christopher Alexander
Many programmers know the name of the architect Christopher Alexander for his work on design patterns that has been adapted into the world of programming. A lot of people know of the, sometimes ridiculed, patterns like strategy (functions!) or visitor (pattern matching!) and some have read the Gang of Four design patterns book that introduced them. A few people know of the Patterns of Software book by Richard P. Gabriel, which is a much more profound reflection on software inspired by the work of Christopher Alexander. And almost nobody has actually read Christopher Alexander's books. (Thanks in advance for reminding me on Twitter that I am mistaken...)
I read Alexander's Notes on the Synthesis of Form a couple of years ago, and used it as one of the sources for ideas in my recent Onward! essay on architecture, design and urban planning, but I did not know his other work. Only recently, after Christopher Alexander died, I finally ordered two books that are most directly about design patterns, The Timeless Way of Building and A Pattern Language.
This post is a somewhat unorganized collection of thoughts triggered by reading of The Timeless Way of Building, including my understanding of Alexander's work, some critical thoughts and on the applications of his ideas to software.
Published: Thursday, 1 September 2022, 2:03 AM
Tags:
academic, research, programming languages, architecture, design
Read the complete article
No-code, no thought? Substrates for simple programming for all

Figure 1. Virtually eliminates your coding load. FLOW-MATIC promotional brochure (1957)
No-code is a hot new topic for programming startups. The idea is to develop a system that allows end-users to do the programming they need without the difficult task of writing code. There are no-code systems for building mobile apps, analysing data and many more.
It is perhaps not a surprise that "eliminating programming load" is not as new idea as some people may think and there is an excellent blog series on no-code history by Instadeq, going back to 1959.
Funnily enough, the 1957 promotional brochure about FLOW-MATIC, a predecessor to COBOL created by Grace Hopper, uses almost the same language that you will find in startup pitch decks today (Figure 1). Of course, in 1957, coding referred to the tedious process of transcribing the desired program to low-level assembler or (more often) directly to machine code and "virtually eliminating your coding load" meant having a symbolic high-level programming language so easy that a reasonably skilled mathematician would be able to use it.
So, is there really anything new about no-code systems? Is it really possible to "eliminate your programming load"? And what would it really take to make some real progress in that direction?
Published: Thursday, 28 April 2022, 11:37 AM
Tags:
academic, research, programming languages
Read the complete article
Pop-up from Hell: On the growing opacity of web programs
I started to learn how to program in high school at the end of the 1990s using a mix of BASIC, Turbo Pascal and HTML with JavaScript. The seed for this blog post comes from my experience with learning how to program in JavaScript, without having much guidance or organized resources. This article continues a theme that I started in my interactive Commodore 64 article, which is to look at past programming systems and see what interesting past ideas have been lost in contemporary systems. Unlike with Commodore 64, which I first used in 2018 in the Seattle Living Computers museum, my perspective on the Early Web may be biased by personal experience. I will do my best to not make this post sound like a grumbling of an old nerd! (I thought this only comes later, but I may have been wrong...)
The 1990s, the web had a fair amount of quirky web pages, often created just for fun. The GeoCities hosting service, which has partly been archived is a witness of this and there are even academic books, such as Dot-Com Design documenting this history.
Some of the quirky things that you could do with JavaScript included creating roll-over effects (making an image change when mouse pointer is over it), creating an animation that follows the cursor as it moves and, of course, annoying the users with all sorts of pop-up windows for both entertaining and advertising purposes. Annoying pop-ups will be the starting point for my blog post, but I'll be using those to make a more general and interesting point about how programs evolve to become more opaque.
This blog post is based on a talk Popup from hell: Reflections on the most annoying 1990s program that I did recently at an (in person!) meeting of the PROGRAMme project. Thanks to everyone who attended for lively discussion and useful feedback!
Published: Friday, 8 October 2021, 1:14 PM
Tags:
academic, research, web, philosophy, talks
Read the complete article
Software designers, not engineers: An interview from alternative universe
While the physicists investigate the nature of the mysterious portal that has recently appeared in North London, several human beings recently came through the portal, which appears to be a gate into an alternative universe. As we understood from the last two people coming through the portal, it seems to be a linked with a universe that is in many ways like ours, reached about the same level of social and technological development, but differs in numerous curious details. The paths through which people in this alternative universe reached similar results as our world are often subtly different.

The most recent visitor from the alternative universe is Ms Zaha Atkinson, who would most likely be titled software engineer in our world, although the title she uses in her home world is software designer. She is a well-known software designer and has been also titled using the strange-sounding title softwarenova, a label that we will soon say more about. As with other technological and societal developments, the alternative universe seems to have arrived at very similar results as our worlds. Software is eating the (alternative) world, but it is built in very different ways. The interview with Ms Zaha Atkinson, presented below, reveals how very different the world of software is when we think of programmers as software designers rather than as software engineers.
This article is a work of fiction. Any resemblance to actual events or persons, living or dead, may or may not be entirely coincidental. It has been largely inspired by the book Designerly Ways of Knowing by Nigel Cross. Ms Zaha Atkinson also may or may not be entirely fictional.
Published: Monday, 19 April 2021, 2:30 PM
Tags:
academic, research, design, philosophy, architecture
Read the complete article
Is deep learning a new kind of programming? Operationalistic look at programming
In most discussions about how to make programming better, someone eventually says something along the lines of "we'll just have to wait until deep learning solves the problem!" I think this is a naively optimistic idea, but it raises one interesting question: In what sense are programs created using deep learning a different kind of programs than those written by hand?

This question recently arose in discussions that we have been having as part of the PROGRAMme project, which explores historical and philosophical perspectives on the question "What is a (computer) program?" and so this article owes much debt to others involved in the project, especially Maël Pégny, Liesbeth De Mol and Nick Wiggershaus.
Many people will intuitively think that, if you train a deep neural network to solve some a problem, you get a different kind of program than if you manually write some logic to solve the problem. But what exactly is the difference? In both cases, the program is a sequence of instructions that are deterministically executed by a machine, one after another, to produce the result.
When reading the excellent book Inventing Temperature by Hasok Chang recently, I came across the idea of operationalism, which I believe provides a useful perspective for thinking about the issue of deep learning and programming. The operationalist point of view was introduced by a physicist Percy Williams Bridgman. To quote: we mean by any concept nothing more than a set of operations; the concept is synonymous with the corresponding set of operations. What does this tell us about deep learning and programming?
Published: Wednesday, 7 October 2020, 2:43 AM
Tags:
programming languages, philosophy, research
Read the complete article
Data exploration calculus: Capturing the essence of exploratory data scripting
Most real-world programming languages are too complex to be studied using formal methods. For this reason, academics often work with simple theoretical languages instead. The λ-calculus is a simple formal language that is often used for talking about functional languages, the π-calculus is a model of concurrent programming and there is an entire book, A Theory of Objects modelling various object-oriented systems.
Animation from Financial Times article "Why the world's recycling system stopped working".
Those calculi try to capture the most interesting aspect of the programming language. This is function application in functional programming, sending of messages in concurrent programming and object construction with inheritance in object-oriented programming.
Recently, I have been working on programming tools for data exploration. In particular, I'm interested in the kind of programming that journalists need to do when they work with data. A good example is the coding done for the Why the world's recycling system stopped working article by Financial Times, which is available on GitHub.
Although data journalists and other data scientists use regular programming languages like Python, the kind of code they write is very different from the kind of code you need to write when building a library or a web application in Python.
In a paper Foundations of a live data exploration environment that was published in February 2020 in the open access Programming Journal, I wanted to talk about some interesting work that I've been doing on live previews in The Gamma. For this, I needed a small model of my programming language.
In the end the most interesting aspect of the paper is the definition of the data exploration calculus, a small programming language that captures the kind of code that data scientists write to explore data. This looks quite different from, say, a λ-calculus and π-calculus. It should be interesting not only if you're planning to do theoretical programming language research about data scripting, but also because it captures some of the atypical properties of the programs that data scientists write...
Published: Tuesday, 21 April 2020, 3:42 PM
Tags:
academic, research, programming languages, thegamma, data science
Read the complete article
What to teach as the first programming language and why
The number of Google search results for the phrase "choosing the first programming language" at the time of writing is 15,800. This illustrates just how debated the issue of choosing the first programming language is. In this blog post, I will not actually try to answer the question posed in the title of the post. I will not discuss what language we should teach as the first one. Instead, I will look at a more interesting question.
I will investigate the arguments that are used in favour of or against particular programming languages in computer science curriculum. I am more interested in the kind of argumentation that is employed to support a particular choice than in the specific languages involved. This approach is valuable for two reasons. First, by looking at the argumentation used, we can learn what educators consider important about computer science. Second, understanding the motivations behind different arguments allows us to make our own debates about the choice of a programming language more informed.
The scope of this blog post is limited to the choice of the first programming language taught in an undergraduate computer science programmes at universities. This means that I will not discuss other important contexts such as choices at a primary or a secondary education level, choices for independent learners and choices in other university degrees that might involve programming.
Note that this blog post is adapted from an essay that I wrote as part of a Postgrduate Certificate for Higher Education programme at University of Kent, so it assumes less knowledge about programming than a typical reader of my blog has. This makes it accessible to a broader audience thinking about education though!
Published: Monday, 2 December 2019, 5:48 PM
Tags:
functional, research, academic, programming languages, philosophy, writing
Read the complete article
Programming as interaction: A new perspective for programming language research
In May, I joined the School of Computing at the University of Kent as a Lecturer (equivalent of Assistant Professor in some other countries). When applying for the job, I spent a lot of time thinking about how to best explain the kind of research that I would like to do. This blog post is a brief summary of my ideas. I'm interested in way too many things, including philosophy and design and data journalism, but this post will be mainly about programming language research. After all, I'm a member of the Programming Languages and Systems group!

Unlike some of my other posts about programming languages, I won't try to convince you that we should be studying programming languages completely differently this time. Instead, I want to describe one simple trick that will make current programming language research much more interesting!
A lot of programming language papers today talk about programs and program properties. In statically typed programming languages, we can check that a program \(e\) has certain type \(\tau\), which means that, when the program is run, it will only produce values of the type. This is very nice, but it misses a fundamental thing about programming. How was this program \(e\) actually constructed?
When programming, you spend most of your time working with programs that are unfinished. This means that they do not do what they are supposed to be (eventually) doing and, very often, they are not well-typed or even syntactically invalid. However, that does not mean that we can afford to ignore them. In many cases, programmers can even run those programs (using REPL or using a notebook environment). In other words, programming language research should not study programs, but should instead study programming!
I'm also writing this because I'll soon be looking for collaborators and PhD students, so if the ideas in this blog post sound interesting to you or if you've been working on something related, please let me know! You can get in touch at @tomaspetricek or email tomas@tomasp.net.
We'll have funding for PhD students from September 2019 and I'm also working on getting money for a post-doc position. All of these are open ended, so if the blog post made you curious (and you wouldn't mind living in Canterbury or London), definitely reach out!
Published: Monday, 8 October 2018, 1:22 PM
Tags:
academic, research, programming languages, data science
Read the complete article
Would aliens understand lambda calculus?
Unless you are a sci-fi author or some secret government agency, the question whether aliens would understand lambda calculus is probably not your main practical concern. However, the question is intriguing because it nicely vividly formulates a fundamental question about our formal mathematical knowledge. Are mathematical theories and results about them invented, i.e. constructed by humans, or discovered, i.e. are they eternal truths that exist regardless of whether there are humans to know them?

The question makes for a fantastic late night pub debate, but how can we go about answering it using a more serious methodology? Is there a paper one can read to better understand the problem? Occasionally, a talk or an online comment by a computer scientist comments on this question, but way too often, people miss the fact that the nature of mathematical entities is one of the fundamental questions of philosophy of mathematics. Alas, all those discussions are carefully hidden in the humanities department!
I believe that knowing a bit about philosophy of mathematics is important if we want to have a meaningful debate about philosophical questions of mathematics (sic!) and so I did a talk on this very subject at CodeMesh 2017. This article is slightly refined and hopefully more polished version of the talk for those who, like me, prefer reading over watching. Keep in mind that the question about the nature of mathematical entities is one of the fundamental questions of an entire academic discipline. As such, this article cannot possibly cover all the relevant discussions. Compared to some other writings in this space, this article is, at least, based on a couple of philosophical books that, I believe, have useful things to say on the subject!
Published: Tuesday, 22 May 2018, 11:27 AM
Tags:
academic, research, programming languages, philosophy
Read the complete article
The design side of programming language design

The word "design" is often used when talking about programming languages. In fact, it even made it into the name of one of the most prestigious academic programming conferences, Programming Language Design and Implementation (PLDI). Yet, it is almost impossible to come across a paper about programming languages that uses design methods to study its subject. We intuitively feel that "design" is an important aspect of programming languages, but we never found a way to talk about it and instead treat programming languages as mathematical puzzles or as engineering problems.
This is a shame. Applying design thinking, in the sense used in applied arts, can let us talk about, explore and answer important questions about programming languages that are ignored when we limit ourselves to mathematical or engineering methods. I think the programming language community is, perhaps unconsciously, aware of this - one of the reviews of my recent PLDI paper said "this is a nice, novel design paper, and the community often wants more design papers in our conferences". The problem is that we we do not know how to write and evaluate work that follows design methodology.
To better understand how design works, I recently read The Philosophy of Design by Glenn Parsons. The book perhaps did not answer many of my questions about design, but it did give me a number of ideas about what design is, what questions it can explore and how those could be relevant for the study of programming languages...
Published: Tuesday, 12 September 2017, 6:42 PM
Tags:
academic, research, programming languages, philosophy, design
Read the complete article
Getting started with The Gamma just got easier
Over the last year, I have been working on The Gamma project, which aims to make data-driven visualizations more trustworthy and to enable large number of people to build visualizations backed by data. The Gamma makes it possible to create visualizations that are built on trustworthy primary data sources such as the World Bank and you can provide your own data source by writing a REST service.
A great piece of feedback that I got when talking about The Gamma is that this is a nice ultimate goal, but it makes it hard for people to start with The Gamma. If you do not want to use the World Bank data and you're not a developer to write your own REST service, how do you get started?
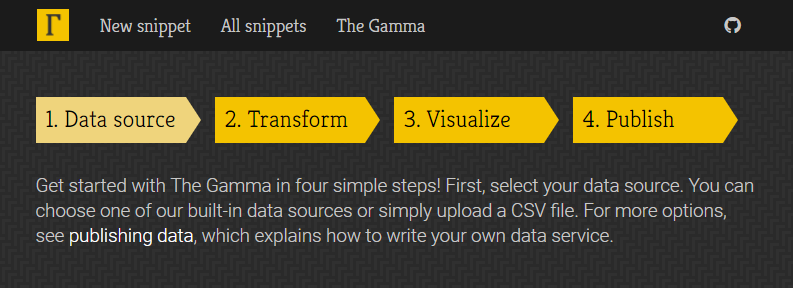
To make starting with The Gamma easier, the gallery now has a new four-step getting started page where you can upload your data as a CSV file or paste it from Excel spreadsheet and create nice visualizations that let your reader explore other aspects of the data.
Head over to The Gamma Gallery to check it out or continue reading to learn more about creating your first The Gamma visualization...
Published: Wednesday, 14 June 2017, 2:27 PM
Tags:
thegamma, data journalism, data science, research, visualization
Read the complete article
The Gamma dataviz package now available!
There were a lot of rumors recently about the death of facts and even the death of statistics. I believe the core of the problem is that working with facts is quite tedious and the results are often not particularly exciting. Social media made it extremely easy to share your own opinions in an engaging way, but what we are missing is a similarly easy and engaging way to share facts backed by data.

This is, in essence, the motivation for The Gamma project that I've been working on recently. After several experiments, including the visualization of Olympic medalists, I'm now happy to share the first reusable component based on the work that you can try and use in your data visualization projects. If you want to get started:
- Check out thegamma-script package on npm
- Minimal example of thegamma-script in action
- How to use thegamma-script in your projects
The package implements a simple scripting language that anyone can use for writing simple data aggregation and data exploration scripts. The tooling for the scripting language makes it super easy to create and modify existing data analyses. Editor auto-complete offers all available operations and a spreadsheet-inspired editor lets you create scripts without writing code - yet, you still get a transparent and reproducible script as the result.
Published: Wednesday, 25 January 2017, 1:31 PM
Tags:
thegamma, data journalism, data science, research, visualization
Read the complete article
Can programming be liberated from function abstraction?

When you start working in the programming language theory business, you'll soon find out that
lambda abstraction and functions break many nice ideas or, at least, make your life very hard.
For example, type inference is easy if you only have var x = ..., but it gets hard once you
want to infer type of x in something like fun x -> ... because we do not know what is
assigned to x. Distributed programming is another example - sending around data is easy, but
once you start sending around function values, things become hard.
Every programming language researcher soon learns this trick. When someone tells you about a nice idea, you reply "Interesting... but how does this interact with lambda abstraction?" and the other person replies "Whoa, hmm, let me think more about this." Then they go back and either give up, because it does not work, or produce something that works, in theory, well with lambda abstraction, but is otherwise quite unusable.
When working on The Gamma project and the little scripting language it runs, I recently went through a similar thinking process. Instead of letting lambda abstraction spoil the party again, I think we need to think about different ways of code reuse.
Published: Tuesday, 27 September 2016, 5:53 PM
Tags:
thegamma, research, programming languages
Read the complete article
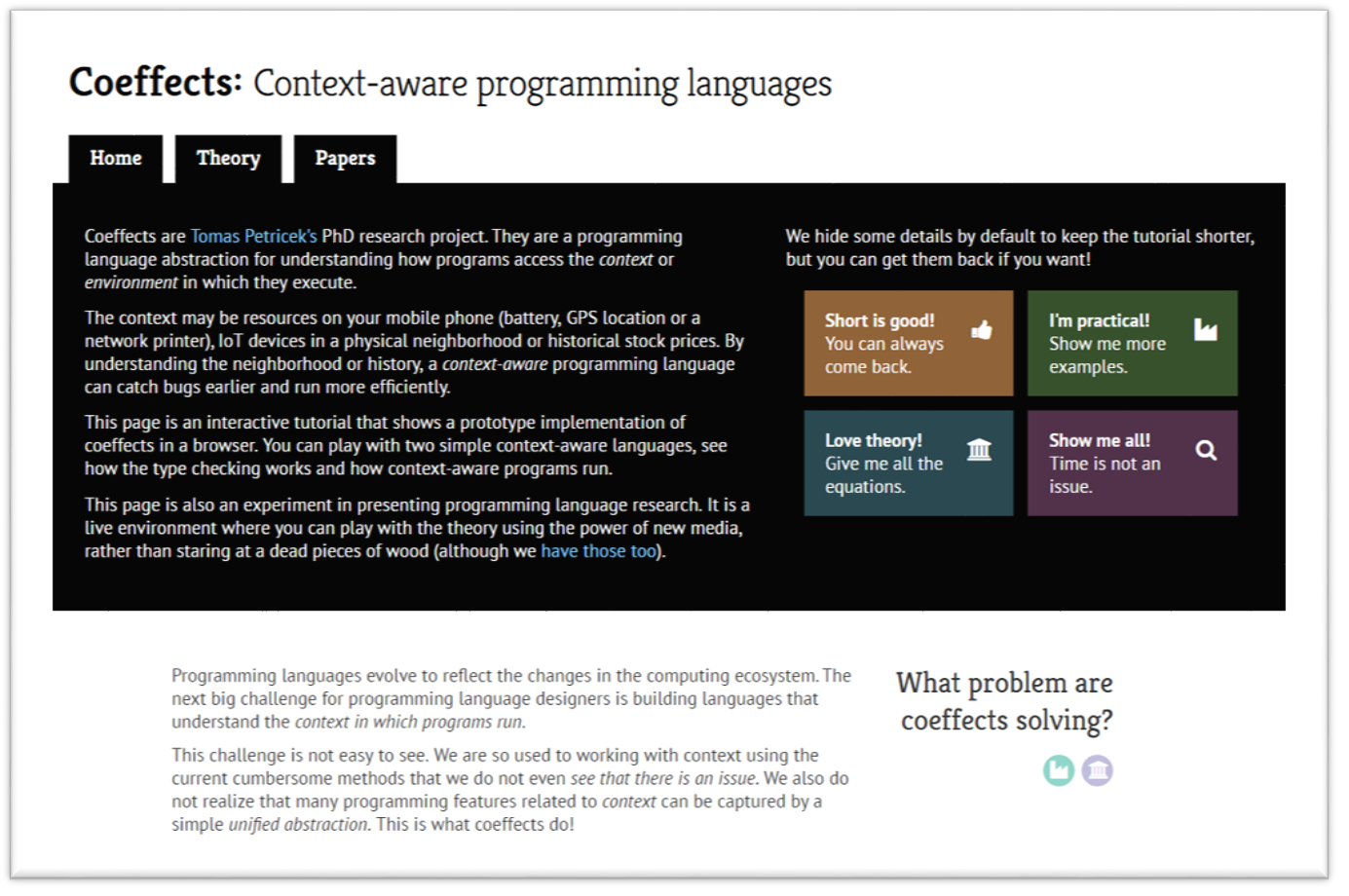
Coeffects playground: Interactive essay based on my PhD thesis
In my PhD thesis, I worked on integrating
contextual information into a type system of functional programming languages. For example,
say your mobile application accesses something from the environment such as GPS sensor or your
Facebook friends. With coeffects, this could be a part of the type. Rather than having type
string -> Person, the type of a function would also include resources and would be
string -{ gps, fb }-> Person. I wrote longer introduction to coeffects on this
blog before.
As one might expect, the PhD thesis is more theoretical and it looks at other kinds of contextual information (e.g. past values in stream-based data-flow programming) and it identifies abstract coeffect algebra that captures the essence of contextual information that can be nicely tracked in a functional language.
I always thought that the most interesting thing about the thesis is that it gives people a nice way to think about context in a unified way. Sadly, the very theoretical presentation in the thesis makes this quite hard for those who are not doing programming language theory.
To make it a bit easier to explore the ideas behind coeffects, I wrote a coeffect playground that runs in a web browser and lets you learn about coeffects, play with two example context-aware languages, run a couple of demos and learn more about how the theory works. Go check it out now or continue below to learn more about some interesting internals!
Published: Tuesday, 12 April 2016, 4:33 PM
Tags:
coeffects, research, functional programming, programming languages
Read the complete article
Philosophy of science books every computer scientist should read
When I tell my fellow computer scientists or software developers that I'm interested in philosophy of science, they first look a bit confused, then we have a really interesting discussion about it and then they ask me for some interesting books they could read about it. Given that Christmas is just around the corner and some of the readers might still be looking for a good present to get, I thought that now is the perfect time to turn my answer into a blog post!
So, what is philosophy of science about? In summary, it is about trying to better understand science. I'll keep using the word science here, but I think engineering would work equally well. As someone who recently spent a couple of years doing a PhD on programming language theory, I find this extremely important for computer science (and programming). How can we make better programming languages if we do not know what better means? And what do we mean when we talk about very basic concepts like types or programming errors?
Reading about philosophy of science inspired me to write a couple of essays on some of the topics above including What can programming language research learn from the philosophy of science? and two essays that discuss the nature of types in programming languages and also the nature of errors and miscomputations. This blog post lists some of the interesting books that I've read and that influenced my thinking (not just) when writing the aforementioned essays.
Published: Thursday, 10 December 2015, 1:42 PM
Tags:
philosophy, research, talks
Read the complete article
In the age of the web: Typed functional-first programming revisited
Most programming languages were designed before the age of web. This matters because the web changes many assumptions that typed functional language designers tak for granted. For example, programs do not run in a closed world, but must instead interact with (changing and likely unreliable) services and data sources, communication is often asynchronous or event-driven, and programs need to interoperate with untyped environments like JavaScript libraries.
How can statically-typed programming languages adapt to the modern world? In this article, I look at one possible answer that is inspired by the F# language and various F# libraries. In F#, we use type providers for integration with external information sources and for integration with untyped programming environments. We use lightweight meta-programming for targeting JavaScript and computation expressions for writing asynchronous code.
This blog post is a shorter version of a ML workshop paper that I co-authored earlier this year and you should see this more as a position statement. I'm not sure if F# and the solutions shown here are the best ones, but I think they highlight very important questions in programming language design that I very much see as unsolved.
The article has two sections. First, I'll go through a simple case study showing how F# can be used to build a client-side web widget. Then, I'll discuss some of the implications for programming language design based on the example.
Published: Wednesday, 9 September 2015, 6:14 PM
Tags:
f#, type providers, web, functional programming, research
Read the complete article
Miscomputation: Learning to live with errors

If trials of three or four simple cases have been made, and are found to agree with the results given by the engine, it is scarcely possible that there can be any error (...).
Charles Babbage, On the mathematical
powers of the calculating engine (1837)
Anybody who has something to do with modern computers will agree that the above statement made by Charles Babbage about the analytical engine is understatement, to say the least.
Computer programs do not always work as expected. There is a complex taxonomy of errors or miscomputations. The taxonomy of possible errors is itself interesting. Syntax errors like missing semicolons are quite obvious and are easy to catch. Logical errors are harder to find, but at least we know that something went wrong. For example, our algorithm does not correctly sort some lists. There are also issues that may or may not be actual errors. For example an algorithm in online store might suggest slightly suspicious products. Finally, we also have concurrency errors that happen very rarely in some very specific scenario.
If Babbage was right, we would just try three or four simple cases and eradicate all errors from our programs, but eliminating errors is not so easy. In retrospect, it is quite interesting to see how long it took early computer engineers to realise that coding (i.e. translating mathematical algorithm to program code) errors are a problem:
Errors in coding were only gradually recognized to be a significant problem: a typical early comment was that of Miller [circa 1949], who wrote that such errors, along with hardware faults, could be "expected, in time, to become infrequent".
Mark Priestley, Science of Operations (2011)
We mostly got rid of hardware faults, but coding errors are still here. Programmers spent over 50 years finding different practical strategies for dealing with them. In this blog post, I want to look at four of the strategies. Quite curiously, there is a very wide range.
Published: Monday, 27 July 2015, 3:15 PM
Tags:
philosophy, research, programming languages
Read the complete article
Against the definition of types
Science is much more 'sloppy' and 'irrational' than its methodological image.
Paul Feyerabend, Against Method (1975)

Programming languages are a fascinating area because they combine computer science (and logic) with many other disciplines including sociology, human computer interaction and things that cannot be scientifically quantified like intuition, taste and (for better or worse) politics.
When we talk about programming languages, we often treat it mainly as scientific discussion seeking some objective truth. This is not surprising - science is surrounded by an aura of perfection and so it is easy to think that focusing on the core scientific essence (and leaving out everything) else is the right way of looking at programming languages.
However this leaves out many things that make programming languages interesting. I believe that one way to fill the missing gap is to look at philosophy of science, which can help us understand how programming language research is done and how it should be done. I wrote about the general idea in a blog post (and essay) last year. Today, I want to talk about one specific topic: What is the meaning of types?
This blog post is a shorter (less philosophical and more to the point) version of an essay that I submitted to Onward! Essays 2015. If you want to get a quick peek at the ideas in the essay, then continue reading here! If you want to read the full essay (or save it for later), you can get the full version from here.
Published: Thursday, 14 May 2015, 4:46 PM
Tags:
philosophy, research
Read the complete article
Stateful computations in F# with update monads

Most discussions about monads, even in F#, start by looking at the well-known standard monads for handling state from Haskell. The reader monad gives us a way to propagate some read-only state, the writer monad makes it possible to (imperatively) produce values such as logs and the state monad encapsulates state that can be read and changed.
These are no doubt useful in Haskell, but I never found them as important for F#.
The first reason is that F# supports state and mutation and often it is just easier
to use a mutable state. The second reason is that you have to implement three
different computation builders for them. This does not fit very well with the F# style
where you need to name the computation explicitly, e.g. by writing async { ... }
(See also my recent blog about the F# Computation Zoo paper).
When visiting the Tallinn university in December (thanks to James Chapman, Juhan Ernits & Tarmo Uustalu for hosting me!), I discovered the work on update monads by Danel Ahman and Tarmo Uustalu on update monads, which elegantly unifies reader, writer and state monads using a single abstraction.
In this article, I implement the idea of update monads in F#. Update monads are
parameterized by acts that capture the operations that can be done on the state.
This means that we can define just a single computation expression update { ... }
and use it for writing computations of all three aforementioned kinds.
Published: Tuesday, 13 May 2014, 4:41 PM
Tags:
f#, research, functional programming, monads
Read the complete article
What can programming language research learn from the philosophy of science?
As someone doing programming language research, I find it really interesting to think about how programming language research is done, how it has been done in the past and how it should be done. This kind of questions are usually asked by philosophy of science, but only a few people have discussed this in the context of computing (or even programming languages).
So, my starting point was to look at the classic works in the general philosophy of science and see which of these could tell us something about programming languages.
I wrote an article about some of these ideas and presented it last week at the second symposium on History and Philosophy of Programming. For me, it was amazing to talk with interesting people working on so many great related ideas! Anyway, now that the paper has been published and I did a talk, I should also share it on my blog:
- What can Programming Language Research Learn from the Philosophy of Science?
- Fairly minimalistic slides from my talk at the symposium
One feedback that I got when I submitted the paper to Onward! Essays last year was that the paper uses a lot of philosophy of science terminology. This was partly the point of the paper, but the feedback inspired me to write a more readable overview in a form of blog post. So, if you want to get a quick peek at some of the ideas, you can also read this short blog (and then perhaps go back to the paper)!
Published: Thursday, 10 April 2014, 6:16 PM
Tags:
research, philosophy
Read the complete article
Coeffects: The next big programming challenge
Many advances in programming language design are driven by some practical motivations. Sometimes, the practical motivations are easy to see - for example, when they come from some external change such as the rise of multi-core processors. Sometimes, discovering the practical motivations is a tricky task - perhaps because everyone is used to a certain way of doing things that we do not even see how poor our current solution is.
The following two examples are related to the work done in F# (because this is what I'm the most familiar with), but you can surely find similar examples in other languages:
-
Multi-core is an easy to see challenge caused by an external development. It led to the popularity of immutable data structures (and functional programming, in general) and it was also partly motivation for asynchronous workflows.
-
Data access is a more subtle challenge. Technologies like LINQ make it significantly easier, but it was not easy to see that inline SQL was a poor solution. This is even more the case for F# type providers. You will not realize how poor the established data access story is until you see something like the WorldBank and R provider or CSV type provider.
I believe that the next important practical challenge for programming language designers is of the kind that is not easy to see - because we are so used to doing things in certain ways that we cannot see how poor they are. The problem is designing languages that are better at working with (and understanding) the context in which programs are executed.
Published: Wednesday, 8 January 2014, 4:31 PM
Tags:
research, coeffects, functional programming, comonads
Read the complete article
The F# Computation Expression Zoo (PADL'14)
F# computation expressions are the syntactic language mechanism that is used by features like sequence expressions and asynchronous workflows. The aim of F# computation expressions is to provide a single syntactic mechanism that provides convenient notation for writing a wide range of computations.
The syntactic mechanisms that are unified by computation expressions include Haskell do
notation and list comprehensions, C# iterators, asynchronous methods and LINQ queries,
Scala for comprehensions and Python generators to name just a few.
Some time ago, I started working on an academic article to explain what makes computation expressions unique - and I think there is quite a few interesting aspects. Sadly, this is often not very well explained and so the general perception is more like this...
Published: Friday, 8 November 2013, 7:42 AM
Tags:
haskell, research, f#, functional programming
Read the complete article
Power of mathematics: Reasoning about functional types
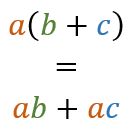
One of the most amazing aspects of mathematics is that it applies to such a wide range of areas. The same mathematical rules can be applied to completely different objects (say, forces in physics or markets in economics) and they work exactly the same way.
In this article, we'll look at one such fascinating use of mathematics - we'll use elementary school algebra to reason about functional data types.
In functional programming, the best way to start solving a problem is to think about the data types that are needed to represent the data that you will be working with. This gives you a simple starting point and a great tool to communicate and develop your ideas. I call this approach Type-First Development and I wrote about it earlier, so I won't repeat that here.
The two most elementary types in functional languages are tuples (also called pairs or product types) and discriminated unions (also called algebraic data types, case classes or sum types). It turns out that these two types are closely related to multiplication and addition in algebra...
Published: Tuesday, 14 May 2013, 5:54 PM
Tags:
f#, research, functional programming
Read the complete article
Processing trees with F# zipper computation
One of the less frequently advertised new features in F# 3.0 is the query syntax.
It is an extension that makes it possible to add custom operations in an F#
computation expression. The standard query { .. } computation uses this to define
operations such as sorting (sortBy and sortByDescending) or operations for taking
and skipping elements (take, takeWhile, ...). For example, you can write:
1: 2: 3: |
|
In this article I'll use the same notation for processing trees using the zipper pattern. I'll show how to define a computation that allows you to traverse a tree and perform transformations on (parts) of the tree. For example, we'll be able to say "Go to the left sub-tree, multiply all values by 2. Then go back and to the right sub-tree and divide all values by 2" as follows:
1: 2: 3: 4: 5: 6: 7: |
|
This example behaves quite differently to the usual query computation. It mostly
relies on custom operations like left, right and up that allow us to navigate
through a tree (descend along the left or right sub-tree, go back to the parent node).
The only operation that does something is the map operation which transforms the
current sub-tree.
This was just a brief introduction to what is possible, so let's take a detailed look at how this works...
Calls Linq.QueryBuilder.Take
Calls Linq.QueryBuilder.SortByDescending
| Node of Tree<'T> * Tree<'T>
| Leaf of 'T
override ToString : unit -> string
| Node(l, r) -> sprintf "(%O, %O)" l r
| Leaf v -> sprintf "%O" v
| Top
| Left of Path<'T> * Tree<'T>
| Right of Path<'T> * Tree<'T>
override ToString : unit -> string
| Top -> "T"
| Left(p, t) -> sprintf "L(%O, %O)" p t
| Right(p, t) -> sprintf "R(%O, %O)" p t
Navigates to the left sub-tree
Navigates to the right sub-tree
Gets the value at the current position
val unit : v:'a -> TreeZipper<'a>
Build tree zipper with singleton tree
--------------------
type unit = Unit
Transform leaves in the current sub-tree of 'treeZip'
into other trees using the provided function 'f'
type TreeZipperBuilder =
new : unit -> TreeZipperBuilder
member Current : tz:TreeZipper<'a> -> 'a
member Current : tz:TreeZipper<'a> -> 'a
member For : tz:TreeZipper<'T> * f:('T -> TreeZipper<'T>) -> TreeZipper<'T>
member Left : tz:TreeZipper<'a> -> TreeZipper<'a>
member Left : tz:TreeZipper<'a> -> TreeZipper<'a>
member Right : tz:TreeZipper<'a> -> TreeZipper<'a>
member Right : tz:TreeZipper<'a> -> TreeZipper<'a>
member Select : tz:TreeZipper<'a> * f:('a -> 'a) -> TreeZipper<'a>
member Select : tz:TreeZipper<'a> * f:('a -> 'a) -> TreeZipper<'a>
...
--------------------
new : unit -> TreeZipperBuilder
| TZ of Tree<'T> * Path<'T>
override ToString : unit -> string
Global instance of the computation builder
type CustomOperationAttribute =
inherit Attribute
new : name:string -> CustomOperationAttribute
member AllowIntoPattern : bool
member IsLikeGroupJoin : bool
member IsLikeJoin : bool
member IsLikeZip : bool
member JoinConditionWord : string
member MaintainsVariableSpace : bool
member MaintainsVariableSpaceUsingBind : bool
member Name : string
...
--------------------
new : name:string -> CustomOperationAttribute
type ProjectionParameterAttribute =
inherit Attribute
new : unit -> ProjectionParameterAttribute
--------------------
new : unit -> ProjectionParameterAttribute
Calls TreeZipperBuilder.Left
Calls TreeZipperBuilder.Select
Transform the current sub-tree using 'f'
Calls TreeZipperBuilder.Up
Calls TreeZipperBuilder.Right
Calls TreeZipperBuilder.Top
Published: Wednesday, 19 December 2012, 2:22 PM
Tags:
f#, haskell, research, monads, linq
Read the complete article
Applicative functors: definition and syntax
In a recent blog post, Edward Z. Yang talks about applicative functors.
He mentions two equivalent definitions of applicative functors - the standard
definition used in Haskell libraries (Applicative) and an alternative that
has been also presented in the original paper, but is generally less
familiar (Monoidal).
The standard definition makes a perfect sense with the standard uses in Haskell,
however I always preferred the alternative definition. Edward uses the alternative
(Monoidal) definition to explain the laws that should hold about applicative
functors and to explain commutative applicative functors, but I think it
is even more useful.
The Monoidal definition fits nicely with a trick that you can use to
encode applicative functors in C# using LINQ and I also used it as
a basis for an F# syntax extension that allows writing code using applicative
functors in a similar style as using monads (which is discussed in my draft
paper about writing abstract computations in F#). And I also think that
commutative applicative functors deserve more attention.
Published: Tuesday, 21 August 2012, 2:23 PM
Tags:
research, haskell, f#
Read the complete article
Why type-first development matters

Using functional programming language changes the way you write code in a number of ways. Many of the changes are at a small-scale. For example, you learn how to express computations in a shorter, more declarative way using higher-order functions. However, there are also many changes at a large-scale. The most notable one is that, when designing a program, you start thinking about the (data) types that represent the data your code works with.
In this article, I describe this approach. Since the acronym TDD is already taken, I call the approach Type-First Development (TFD), which is probably a better name anyway. The development is not driven by types. It starts with types, but the rest of the implementation can still use test-driven development for the implementation.
This article demonstrates the approach using a case study from a real life: My example is a project that I started working on with a friend who needed a system to log journeys with a company car (for expense reports). Using the type-first approach made it easier to understand and discuss the problem.
In many ways, TFD is a very simple approach, so this article just gives a name to a practice that is quite common among functional and F# programmers (and we have been teaching it at our F# trainings for the last year)...
Published: Thursday, 16 August 2012, 12:21 AM
Tags:
functional, f#, research
Read the complete article
The theory behind covariance and contravariance in C# 4
In C# 4.0, we can annotate generic type parameters with out and in annotations to
specify whether they should behave covariantly or contravariantly. This is mainly
useful when using already defined standard interfaces. Covariance means that you can use
IEnumerable<string> in place where IEnumerable<object> is expected. Contravariance
allows you to pass IComparable<object> as an argument of a method taking IComparable<string>.
So far, so good. If you already learned about covariance and contravariance in C# 4, then the above two examples are probably familiar. If you're new to the concepts, then the examples should make sense (after a bit of thinking, but I'll say more about them). However, there is still a number of questions. Is there some easy way to explain the two concepts? Why one option makes sense for some types and the other for different types? And why the hell is it called covariance and contravariance anyway?
In this blog post, I'll explain some of the mathematics that you can use to think about covariance and contravariance.
Published: Tuesday, 19 June 2012, 2:24 PM
Tags:
c#, research
Read the complete article
F# in Academia: Present at upcoming events!
The F# language was born as a combination of the pragmatic and real-world .NET platform and functional programming, which had a long tradition in academia. Many useful ideas or libraries in F# (like asynchronous workflows and first-class events) are inspored by research in functional programming (namely, the work on monads, continuations and functional reactive programming).
Exchanging the ideas between the research community and the real-world is one of the areas where F# excels. Indeed, the first applicatiosn of F# inside Microsoft (in the Machine Learning group at Cambridge) were all about this - combining research in machine learning with a language that can be easily used in practice.
However, F# and the F# users also made numerous contributions to the programming language research community. Influential ideas that come from F# include active patterns and the F# style of meta-programming for translating F# to JavaScript). I think there is a lot more that the academic community can learn from the F# community, so I'd like to invite you to talk about your ideas at two upcoming academic events!
What, why, when, where and how? Continue reading!
Published: Monday, 16 April 2012, 12:19 AM
Tags:
presentations, f#, haskell, research
Read the complete article
TryJoinads (VII.) - Implementing joinads for async workflows
The article Asynchronous workflows and joinads gives numerous
examples of programming with asynchronous workflows using the match! construct.
Briefly, when matching on multiple asynchronous workflows, they are executed in
parallel. When pattern matching consists of multiple clauses, the clause that matches
on computations that complete first gets executed. These two behaviours are
implemented by the Merge and the Choose operation of joinads. Additionally,
asynchronous workflows require the Alias operation, which makes it possible to
share the result of a started asynchronous workflow in multiple clauses.
In this article, we look at the definition of the additional AsyncBuilder
operations that enable the match! syntax. We do not look at additional examples
of using the syntax, because these can be found in a previous article.
Note: This blog post is a re-publication of a tutorial from the TryJoinads.org web page. If you read the article there, you can run the examples interactively and experiment with them: view the article on TryJoinads.
Published: Friday, 23 March 2012, 5:21 PM
Tags:
asynchronous, f#, research, joinads
Read the complete article
TryJoinads (VI.) - Parsing with joinads
In functional programming, parser combinators are a powerful way of writing parsers. A parser is a function that, given some input, returns possible parsed values and the rest of the input. Parsers can be written using combinators for composition, for example run two parsers in sequence or perform one parser any number of times.
Parsers can also implement the monad structure. In some cases, this makes the parser
less efficient, but it is an elegant way of composing parsers and we can also benefit
from the syntactic support for monads. In this article, we implement a simple parser
combinators for F# and we look what additional expressive power we can get from the
joinad structure and match! construct. This article is largely based on a
previous article "Fun with Parallel Monad Comprehensions", which can be found on the
publications page.
Note: This blog post is a re-publication of a tutorial from the TryJoinads.org web page. If you read the article there, you can run the examples interactively and experiment with them: view the article on TryJoinads.
Published: Wednesday, 21 March 2012, 4:27 PM
Tags:
f#, joinads, research
Read the complete article
TryJoinads (V.) - Implementing the option joinad
This article shows how to implement the joinad structure for one of the
simplest monads - the option<'T> type. This is a slightly oversimplified example.
The match! construct can be used to write patterns that specify that a monadic
value (in this case option<'T>) should contain a certain value, or we can specify
that we do not require a value. When working with options, this means the same thing
as matching the value against Some and against _, respectively.
However, the example demonstrates the operations that need to be implemented and their type signatures. Later articles give more interesting examples including parsers and asynchronous workflows (and you can explore other examples if you look at the FSharp.Joiands source code at GitHub).
Note: This blog post is a re-publication of a tutorial from the TryJoinads.org web page. If you read the article there, you can run the examples interactively and experiment with them: view the article on TryJoinads.
Published: Friday, 2 March 2012, 1:24 PM
Tags:
f#, research, joinads
Read the complete article
TryJoinads (IV.) - Concurrency using join calculus
Join calculus provides a declarative way of expressing asynchronous synchronization
patterns. It has been use as a basis for programming languages (JoCaml and COmega), but also
as a basis for libraries (embedded in C# and Scala). Using joinads, it is possible to
embed join calculus in F# with a nice syntax using the match! construct. Formally,
join calculus does not form a monad, but it can be viewed as a version of joinad
as described in the first paper on joinads.
The programming model is based on channels and join patterns. A channel can be viewed as a thread-safe mailbox into which we can put values without blocking the caller. In some sense, this is quite similar to F# agents. A join pattern is then a rule saying that a certain combination of values in channels should trigger a specific reaction (and remove values from the channels). The ability to match on multiple channels distinguishes join calculus from F# agents.
Note: This blog post is a re-publication of a tutorial from the TryJoinads.org web page. If you read the article there, you can run the examples interactively and experiment with them: view the article on TryJoinads.
Published: Wednesday, 22 February 2012, 5:38 PM
Tags:
f#, research, joinads, asynchronous, parallel
Read the complete article
TryJoinads (III.): Agent-based programming
Another area where the match! syntax can be used is when programming with F# agents,
implemented by the MailboxProcessor type. Formally, agents do not form the monad
structure in a useful way - when programming with agents, we do not compose a new agents,
but instead we write code that (imperatively) receives messages from the agent's mailbox
and handles them.
This article demonstrates an agent { ... } computation builder that can be used for
implementing the body of an agent. Normally, the body of an agent is an asynchronous
workflow. The code in the body uses let! to perform asynchronous operations, most
importantly to call inbox.Receive to get the next message from the inbox. When the
agent intends to handle only certain kinds of messages, it can use inbox.Scan. When
using the agent builder, pattern matching on messages can be written using match! and
it is possible to write code that ignores certain types of messages simply by writing an
incomplete pattern matching.
Note: This blog post is a re-publication of a tutorial from the TryJoinads.org web page. If you read the article there, you can run the examples interactively and experiment with them: view the article on TryJoinads.
Published: Monday, 20 February 2012, 12:36 PM
Tags:
joinads, research, f#, parallel, asynchronous
Read the complete article
TryJoinads (II.): Task-based parallelism
The implementation of joinad operations for the Task<'T> type is quite similar to the
implementation of Async<'T>, because the two types have similar properties. They both
produce at most one value (or an exception) and they both take some time to complete.
Just like for asynchronous workflows, pattern matching on multiple computations using
match! gives us a parallel composition (with the two tasks running in parallel) and
choice between clauses is non-deterministic, depending on which clause completes first.
Unlike asynchronous workflows, the Task<'T> type does not require any support for
aliasing. A value of type Task<'T> represents a running computation that can be
accessed from multiple parts of program. In this sense, the type Async<'T> is more
similar to a function unit -> Task<'T> than to the type Task<'T> itself.
The key difference between tasks and asynchronous workflows is that the latter provides better support for writing non-blocking computations that involve asynchronous long-running operations such as I/O or waiting for a certain event. Tasks are more suitable for high-performance CPU-intensive computations.
Note: This blog post is a re-publication of a tutorial from the TryJoinads.org web page. If you read the article there, you can run the examples interactively and experiment with them: view the article on TryJoinads.
Published: Friday, 17 February 2012, 1:10 PM
Tags:
research, f#, parallel, joinads
Read the complete article
TryJoinads (I.) - Asynchronous programming
Asynchronous workflows provide a way of writing code that does not block a thread
when waiting for a completion of long-running operation such as web service call,
another I/O operation or waiting for the completion of some background operation.
In this article, we look at the new expressive power that joinads add to
asynchronous workflows written using the async { ... } block in F#.
Note: This blog post is a re-publication of a tutorial from the TryJoinads.org web page. If you read the article there, you can run the examples interactively and experiment with them: view the article on TryJoinads.
Published: Monday, 13 February 2012, 5:35 PM
Tags:
f#, research, joinads
Read the complete article
Introducing TryJoinads.org
If you have been following my blog, you've probably already heard of joinads. It is a research extension of F# computation expressions (or monads in Haskell). The extension makes computation expressions more useful in domains like parallel, concurrent and reactive programming. However, it can be used for any type of computation including, for example, parsers. If you're interested in detailed description, you can find it in two academic papers that I blogged about previously: PADL 2011 and Haskell 2011.
The extension adds a keyword match! - as the syntax suggests, it is akin to pattern
matching using match, but instead of pattern matching on values, you can pattern match
on computations like Async<'T> (or on other monadic values). Just like other features of
computation expressions, the match! syntax is translated to applications of several
methods defined by the computation builder.
I won't say more about joinads in this post, because you can now easily try joinads yourself...
Published: Monday, 13 February 2012, 4:21 PM
Tags:
parallel, asynchronous, f#, research, links, joinads
Read the complete article
Programming with F# asynchronous sequences

In F#, we can represent asynchronous operations that do not block threads and eventually
return a value of type 'T using asynchronous workflows Async<'T>.
Asynchronous workflows can be easily constructed using the computation expression syntax
async { ... } and there are also a few combinators that express more advanced
composition (such as parallel composition or fork-join parallelism).
Sometimes, we need to use asynchronous operations that return more than just one value. For example, when downloading data from the internet, we would like to create an asynchronous sequence that returns the data in chunks as they become available.
One way to represent asynchronous operations that produce multiple values is to use
the IObservable<'T> type from .NET. This isn't always the best option
though. Observables implement push-based model, which means that chunks of data are
generated as quickly as possible (until all chunks are emitted). What if we wanted to take
the chunks one-by-one after the previous chunk is processed?
In this article, I describe asynchronous sequences. An asynchronous sequence is a simple, yet very powerful concept based on asynchronous workflows. It follows the same core model: results are generated on demand and asynchronously. Unlike asynchronous workflows, asynchronous sequences can be called (on demand) to generate multiple values until the end of the sequence is reached.
I first discussed asynchronous sequences with Don Syme, Dmitry Lomov and Brian McNamara in an email thread a long time ago. Thanks to Don for enthusiasm about the concept and for the first implementation of some of the combinators!
Published: Thursday, 11 August 2011, 11:30 PM
Tags:
functional, asynchronous, f#, research
Read the complete article
Extending Monads with Pattern Matching (Haskell 2011)
Some time ago, I wrote a paper about joinads and the match! extension
of the F# language. The paper was quite practically oriented and didn't go into much details about
the theory behind joinads. Many of the examples from the F# version relied on some
imperative features of F#. I believe that this is useful for parctical programming, but I
also wanted to show that the same idea can work in the purely functional context.
To show that joinads work in the pure setting, I created a Haskell version of the idea. The implementation (available below) is quite simple and consists of a pre-processor for Haskell source files and numerous examples. However, more important part of the recent work of joinads is a more detailed theoretical background.
The theory of joinads, together with the language design of Haskell extension that implements it is discussed in a paper Extending Monads with Pattern Matching, which was accepted for publication at the Haskell Symposium 2011. Here is the abstract of the paper:
Sequencing of effectful computations can be neatly captured using monads and elegantly written using
do notation. In practice such monads often allow additional ways of composing computations,
which have to be written explicitly using combinators.
We identify joinads, an abstract notion of computation that is stronger than monads and captures
many such ad-hoc extensions. In particular, joinads are monads with three additional operations:
one of type m a -> m b -> m (a, b) captures various forms of parallel composition,
one of type m a -> m a -> m a that is inspired by choice and one of type m a -> m (m a)
that captures aliasing of computations. Algebraically, the first two operations form a
near-semiring with commutative multiplication.
We introduce docase notation that can be viewed as a monadic version of case. Joinad laws
make it possible to prove various syntactic equivalences of programs written using docase
that are analogous to equivalences about case. Examples of joinads that benefit from the notation
include speculative parallelism, waiting for a combination of user interface events, but also
encoding of validation rules using the intersection of parsers.
Links to the full paper, source code and additional materials are available below.
Published: Wednesday, 20 July 2011, 12:19 AM
Tags:
parallel, writing, research, haskell, joinads
Read the complete article
Fun with parallel monad comprehensions (The Monad.Reader)
This article is a re-publication of an article that I wrote some time ago for The Monad.Reader magazine, which is an online magazine about functional programming and Haskell. You can also read the article in the original PDF format as part of the Issue 18 (together with two other interesting articles). The samples from the article can be found on Github.
Monad comprehensions have an interesting history. They were the first syntactic extension for
programming with monads. They were implemented in Haskell, but later replaced with plain list
comprehensions and monadic do notation. Now, monad comprehensions are back in Haskell,
more powerful than ever before!
Redesigned monad comprehensions generalize the syntax for working with lists. Quite interestingly, they also generalize syntax for zipping, grouping and ordering of lists. This article shows how to use some of the new expressive power when working with well-known monads. You'll learn what "parallel composition" means for parsers, a poor man's concurrency monad and an evaluation order monad.
Published: Tuesday, 19 July 2011, 11:28 PM
Tags:
haskell, research, parallel
Read the complete article
Safer asynchronous workflows for GUI programming
In the previous article, I discussed how to use F# asynchronous workflows for creating reactive user-interfaces. One of the main concerns was to avoid blocking the GUI thread (to prevent the user-interface from freezing). The workflow shouldn't perform any CPU-intensive computation when running on the GUI thread.
The standard F# library provides two ways to run a computation on a background thread from
an asynchronous workflow. The StartChild operation starts an operation
in the thread pool and returns a workflow that can be called using asynchronous (non-blocking)
let! construct. The SwitchToThreadPool operation can be called
using do! and resumes the rest of the workflow on a background thread.
When using the SwitchToThreadPool operation, we also need to eventually use
SwitchToContext to transfer the execution back to the GUI thread (after
completing the CPU-intensive calculations). In this article, I describe a variation of
F# asynchronous workflows that keeps track of the running thread in the type of the
computation. As a result, calling a workflow that should be executed on a GUI thread
from a background thread is a compile-time error as opposed to failing at runtime.
Published: Wednesday, 15 June 2011, 9:36 PM
Tags:
research, f#, asynchronous, functional
Read the complete article
Writing non-blocking user-interfaces in F#
F# asynchronous workflows are best known as a way to write efficient I/O operations
or as an underlying mechanism of F# agent-based programming (using the MailboxProcessor
type). However, they are also very useful for user-interface programming. I think this is
a very interesting and important area, so I already wrote and talked about this topic -
it is covered in Chapter 16 of my book (there
is a free excerpt)
and I talked about it at F#unctional Londoners
meeting.
Many applications combine user-interface programming (such as waiting for an event asynchronously)
with some CPU-intensive tasks. This article looks at an example of such application and I'll explain
how to avoid blocking the user-interface when doing the CPU-intensive task.
The article starts with an example that is wrong and blocks the user-interface when doing data processing.
Then I'll show you two options for fixing the problem. The three most important
functions from the standard F# library that I'll discuss are Async.StartChild and
Async.SwitchToThreadPool with Async.SwitchToContext.
This is the first article of a mini-series. In the next article, I'll demonstrate a simple
wrapper for F# async that makes it more difficult to write wrong
programs. The wrapper keeps the desired thread (GUI or background) in the type of the
computations and code that would block the user interface will not type-check. But first,
let's look at the example...
Published: Friday, 10 June 2011, 11:36 PM
Tags:
research, asynchronous, f#, functional
Read the complete article
Explicit speculative parallelism for Haskell's Par monad
Haskell provides quite a few ways for writing parallel programs, but none of them is fully automatic. The programmer has to use some annotations or library to run computations in parallel explicitly. The most recent paper (and library) for writing parallel programs follows the latter approach. You can find more information about the library in a paper by Simon Marlow et al. A monad for deterministic parallelism and it is also available on Hackage. However, I'll explain all the important bits that I'll use in this article.
The library provides an explicit way for writing parallel programs using a Par monad. The library contains
constructs for spawning computations and sharing state using blocking variables. However, the whole programming model
is fully deterministic. I believe that it is sometimes useful to lift the determinacy requirement.
Some programs are deterministic, but the fact cannot be (easily) automatically verified. For example, say you have two functions
fib1 and fib2. They both give the same result, but each of them is more efficient
than the other one on certain inputs. To calculate a Fibonacci number, the program could speculatively
try to evaluate both functions in parallel and return the result of the one that finishes first.
Unfortunately, this cannot be safely implemented using a fully deterministic library. In this article, I'll show some
examples where speculative parallelism can be useful and I'll talk about an extension to the Par monad
that I implemented (available on GitHub). The extension allows
programmers to write speculative computations, provided that they manually verify that their code is
deterministic.
Published: Tuesday, 17 May 2011, 1:59 PM
Tags:
research, haskell, parallel
Read the complete article
Variations in F#: Research compiler with Joinads and more!
In this article, I'll write about an experimental extension for F# that I call joinads. If you're following my blog, you may have seen an academic paper that I wrote about it some time ago. Anyway, the motivation for the extension is that there are many useful programming models for reactive, concurrent and parallel programming that would deserve some syntactic support in the programming language.
For example, when programming with futures (the Task<T> type),
you may want to implement logical "or" operator for tasks that returns true
immediately when the first task completes returning true. When programming with
events (the IObservable<T> type),
we'd like to wait for the event that happens first. Finally, when programming using agents,
we sometimes need to wait only for certain types of messages. All of these problems can
be solved, but require the use of (sometimes fairly complicated) functions. Joinads make
it possible to solve them directly using the match! syntax. For example, here
is the "or" operator for tasks:
1: future { 2: match! after 100 true, after 1000 false with 3: | !true, _ -> return true 4: | _, !true -> return true 5: | !a, !b -> return a || b }
I'll write more about this example (and the implementation) in a later article. This article focuses on the compiler extension itself. I created a first implementation of the idea above during my internship with Don Syme at MSR Cambridge, but then changed it quite a bit when writing the academic paper mentioned above. However, I never released the source code.
Thanks to the open-source release of F# it is now quite easy to modify the F# compiler and make the modifications available, so I decided I should finally release my F# extensions. I also recently blogged about encoding idioms (also called applicative functors) in C#. I was wondering how to do that in F# and so I also created a simple extension computations based on this abstraction. The support for idioms is just an experiment, but it could be useful, for example, for programming with formlets. You'll find more about it at the end of the article.
You can find the source code on my GitHub (there is also a link compiled binaries at the end of the article). The source code is cloned from an F# Mono repository, which means that it should build on Linux and MacOS too.
Full name: JoinadsDemo.future
Full name: JoinadsDemo.after
type: bool
implements: IComparable
implements: IConvertible
implements: IComparable<bool>
implements: IEquatable<bool>
inherits: ValueType
type: bool
implements: IComparable
implements: IConvertible
implements: IComparable<bool>
implements: IEquatable<bool>
inherits: ValueType
Published: Friday, 25 March 2011, 12:04 AM
Tags:
research, f#, joinads
Read the complete article
Beyond the Monad fashion (II.): Creating web forms with LINQ
The LINQ query syntax can be used for various things. Aside from writing queries, you can also use it to encode any monads. This has become a fashionable topic, so you can learn more about it at many .NET conferences (for example GOTO 2011). There are also many blog posts on this topic and I explained it in details in Chapter 12 of my book, which is available as a free sample chapter (PDF).
However, you can also use LINQ syntax for writing different types of computations. In a
previous blog post, I introduced idioms
(also called applicative functors) and I demonstrated how to use the join syntax in LINQ
to write computations based on idioms. We looked at a slightly boring, but simple example - zipping of lists - and
we also implemented matrix transposition.
In this blog post, we look at a more exciting example. I explain formlets, which is an idiom for building web forms. Formlets give us an elegant functional way to create reusable components that encapsulate both visual aspect (HTML) and behavior (processing of requests). You can think of them as functional ASP.NET controls. Formlets come from the Links project and they are now used in commercial products like WebSharper. In this article, you'll see that we can (mis)use LINQ to get a nicer syntax for writing code using formlets. My C# implementation of formlets is based on a nice F# formlets by Mauricio Scheffer.
Published: Monday, 14 March 2011, 5:14 PM
Tags:
c#, research
Read the complete article
Beyond the Monad fashion (I.): Writing idioms in LINQ
Thanks to LINQ and Erik Meier, monads have become a fashionable topic in the C# developer community.
Indeed, no serious developer conference on .NET can get away without having a talk on monads. The attractive
thing about LINQ and monads is that the SelectMany operator roughly corresponds to the bind
function that defines a monad. In practice, LINQ is used for working with collections of data (IEnumerable<T>),
but you can also define bind (i.e. SelectMany) for some other data types and use the LINQ syntax
for working with other types. You won't be really using the full LINQ syntax. You'll probably use just nested
from clauses (for binding) and select at the end to return the result.
However, monads are not the only notion of computation that we can work with. More interestingly, they are also not the only notion of computation that you can encode using LINQ! In this article, I'll briefly introduce idioms (also called applicative functors), which is another useful abstract type of computations. Idioms can be used for a few things that cannot be done using monads.
A provocative summary of this article is: "Everyone who tells you that LINQ is a monad is wrong!"
The truth is that LINQ syntax can be used for encoding queries (obviously), monads (as you were told), but also for idioms as you'll learn today (and quite possibly for other types of computations). In this article, we look at a basic example, but I'll describe a more complex real-world scenario in the next blog post.
Published: Thursday, 10 March 2011, 1:26 PM
Tags:
c#, research, functional
Read the complete article
Reactive, parallel and concurrent programming in F# (PADL 2011)
Don Syme blogged about a paper on the F# Asynchrounous Programming Model that I helped to write. Without any doubt, the asynchronous programming features of F# are one of the reason for its success and also influence other teams in Microsoft. However, I'm very glad that there is now also an academic paper that makes this idea accessible to the academic community. I believe that the ideas could evolve in interesting ways when used in other programming languages and also, it is now easier to create research projects that build on top of the F# model.
Don already mentioned that we have another paper accepted at PADL. The paper describes work that started during my internship at Microsoft Research in 2009. It presents a simple language extension for computation expressions that makes them even more useful in some reactive, concurrent and parallel programming models. Note that this is only a research project and there are currently no plans to support the extension in the F# language (although, if there will, eventually, be an open-source F# release, then you'll hear about the extension again...)
Here is the abstract of the paper (accepted at PADL 2011) and a PDF download link:
Joinads: A retargetable control-flow construct for reactive, parallel and concurrent programming
Modern challenges led to a design of a wide range of programming models for reactive, parallel and concurrent programming, but these are often difficult to encode in general purpose languages. We present an abstract type of computations called joinads together with a syntactic language extension that aims to make it easier to use joinads in modern functional languages.
Our extension generalizes pattern matching to work on abstract computations. It keeps a familiar syntax and semantics of pattern matching making it easy to reason about code, even in a non-standard programming model. We demonstrate our extension using three important programming models – a reactive model based on events; a concurrent model based on join calculus and a parallel model using futures. All three models are implemented as libraries that benefit from our syntactic extension. This makes them easier to use and also opens space for exploring new useful programming models.
- Download the full text (PDF, pre-publication draft)
The paper can still be revised before the final publication, so any comments and suggestions for improvement are largely welcome. You can contact me either via comments (below) or using email at tomas@tomasp.net. I would be also quite interested to hear from anybody who would like to implement similar feature in other programming languages (for example Haskell or Scala).
Published: Monday, 25 October 2010, 12:00 AM
Tags:
f#, research, links, joinads
Read the complete article
The Duality of Object and Event references
Mathematical duality [2] is a very useful and elegant concept that gives us a nice way of speaking about objects or structures that behave in some way exactly conversely. There is no clear definition of what duality is. However, the idea is that when we have two structures that behave conversely and we know that something is true about the first one, then we get the opposite statement about the other structure "for free" (if you know how to translate from one structure to the other).
In this article, I'll talk about an interesting example of duality that (to my best knowledge) wasn't described by anyone before. The two dual structures are references between objects in a normal program and references between events in a reactive application. The statement that is going to become obvious thanks to the duality principle is describing which of the objects (or events) are garbage and can be safely collected by garbage collector.
This topic is in much more details discussed in a paper [4] I wrote with Don Syme and that I presented at the ISMM Workshop (see also my trip report from PLDI). In this article, I'll try to give an accessible description of the most interesting idea from the paper...
Published: Monday, 19 July 2010, 4:58 PM
Tags:
academic, research
Read the complete article