Pop-up from Hell On the growing opacity of web programs
I started to learn how to program in high school at the end of the 1990s using a mix of BASIC, Turbo Pascal and HTML with JavaScript. The seed for this blog post comes from my experience with learning how to program in JavaScript, without having much guidance or organized resources. This article continues a theme that I started in my interactive Commodore 64 article, which is to look at past programming systems and see what interesting past ideas have been lost in contemporary systems. Unlike with Commodore 64, which I first used in 2018 in the Seattle Living Computers museum, my perspective on the Early Web may be biased by personal experience. I will do my best to not make this post sound like a grumbling of an old nerd! (I thought this only comes later, but I may have been wrong...)
The 1990s, the web had a fair amount of quirky web pages, often created just for fun. The GeoCities hosting service, which has partly been archived is a witness of this and there are even academic books, such as Dot-Com Design documenting this history.
Some of the quirky things that you could do with JavaScript included creating roll-over effects (making an image change when mouse pointer is over it), creating an animation that follows the cursor as it moves and, of course, annoying the users with all sorts of pop-up windows for both entertaining and advertising purposes. Annoying pop-ups will be the starting point for my blog post, but I'll be using those to make a more general and interesting point about how programs evolve to become more opaque.
This blog post is based on a talk Popup from hell: Reflections on the most annoying 1990s program that I did recently at an (in person!) meeting of the PROGRAMme project. Thanks to everyone who attended for lively discussion and useful feedback!
Pop-ups and the Internet's original sin
As far as I can tell, the necessary technical components for the most annoying pop-up that I will
cover in this blog post have been in place since 1995 when JavaScript was first introduced
in Netscape Navigator 2.0. The library of standard JavaScript functions included
the window.open and also window.onbeforeunload from the very start. There was nothing evil
about opening new windows in your web applications. After all, many regular desktop applications
still open new windows when you open a detailed view or start writing a new email.

Figure 1. Pop-up advertisement from the 1990s
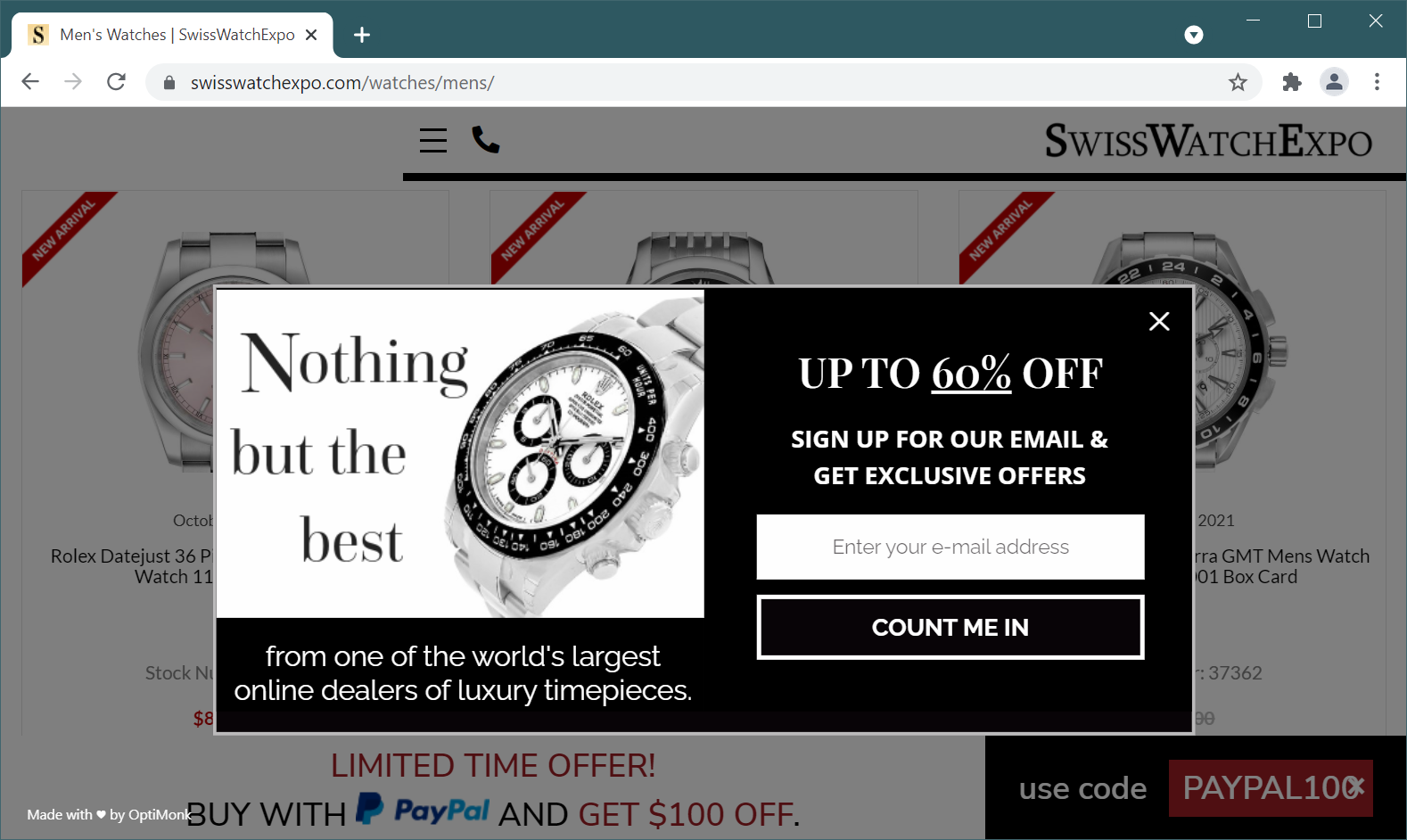
Figure 2. "Pop-up" advertisement from the 2020s
As told in The Internet's Original Sin,
the first use of window.open for advertising was probably at the Tripod.com
web hosting site, which used it to disassociate the advertisements from the (potentially
not-safe-for-work) content hosted on the site by its users.
Since then, pop-ups became "one of the most hated tools in the advertiser's toolkit."
The early web allowed opening pop-ups whenever a web page wanted. You could successfully
invoke window.open when a web page was loading. By changing the focus, the web page could
also make the pop-up appear underneath the main browser window, so that the user would only
see it once they close the browser. This technique is apparently known as pop-under
ads. Another annoying trick was to open the advertisement
when the user left a page, by handling the window.onbeforeunload event that was triggered
when the user closed the window or when they navigated somewhere else.
In the early 2000s, web browsers started fighting back by blocking pop-ups. A simple option
was to block all window.open calls and notify the user. More sophisticated blockers block
pop-ups only when loading or unloading, but allowed them, for example, in response to a button
click.
Pop-up blockers did not stop the pop-up ad war for long. So called hover ads,
or in-page pop-ups, recreate the annoying pop-up experience by simulating a pop-up window
inside the page itself. A pop-up blocker cannot detect this, because the pop-up is not created
using some easily identifiable system functionality like window.open, but using standard
HTML elements with some innocently-looking JavaScript to display the element.
In other words, we got from annoying pop-up ads in the 1990s, like the one in Figure 1, to equally annoying in-page pop-up ads in the 2020s, like the one in Figure 2.
Pop-ups and the quirky social web
When I was learning to program JavaScript at high school, I was not interested in creating pop-up ads, but there was a lot of fun and quirky things you could do with pop-up windows. Many of those were documented or used on various GeoCities sites and elsewhere. A unique aspect of the simple web scripting in the late 1990s was that you could always learn how a particular trick works by using the "View source" command in your web browser. This generally worked, because scripts were small enough (so they did not require any sophisticated software engineering methods) and there was no compilation or minification step involved (so you got readable source code). That way, you could learn how a web page implements whatever effect it includes and reuse it in your own web page. (To experience this first-hand, you are welcome to copy the mouse cursor following stars from this page!)
If you were trying to outsmart your friends, the most obvious thing to try was to create a pop-up
window that cannot be closed, by opening exactly the same pop-up in the onbeforeunload event.
Or, even better, open two windows!
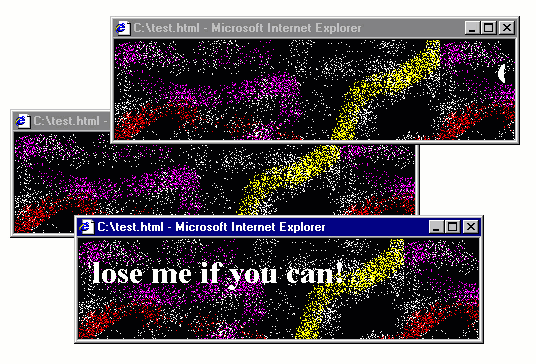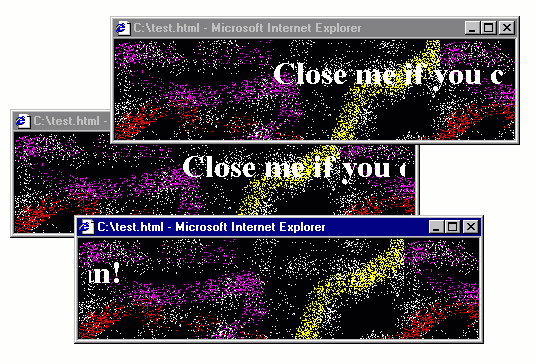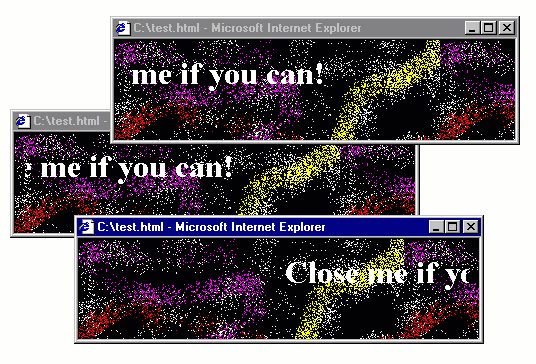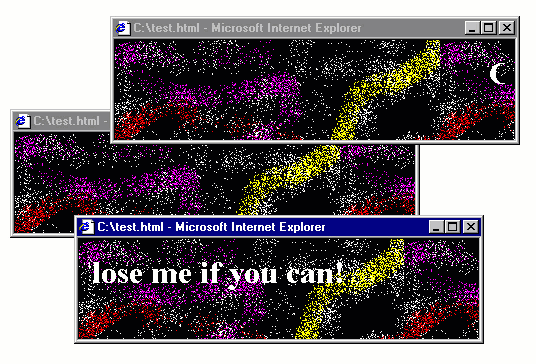
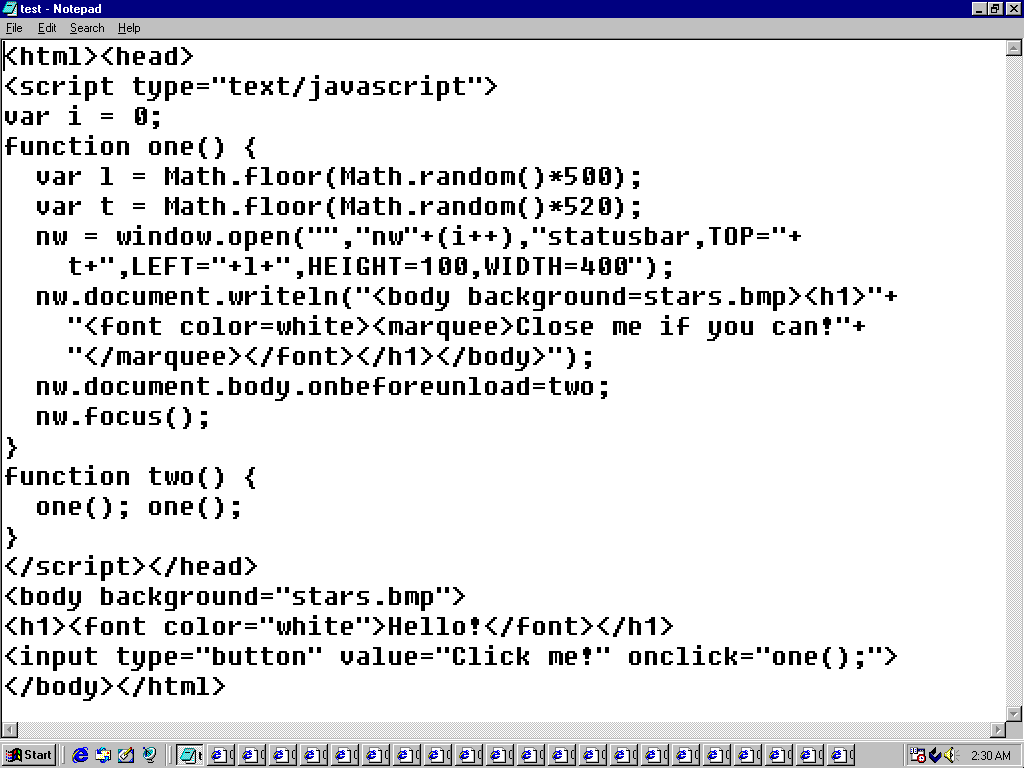
Figure 3. Popup from Hell running in IE5 on Windows 98 virtual machine
The above is an actual implementation of the idea, running in Internet Explorer 5 in Windows 98
in Virtual Box (which you can get from Web Archive).
The code fits in one page. All you need to do is to write a function that opens a pop-up using
window.open, adds some <marquee> to the newly opened window and then registers an event
handler for the body.onbeforeunload event to open two new such windows. As a bonus, I also
created a fancy background using the all time favourite spray tool in Microsoft Paint!
Growing opacity of web programs
My reason for talking about pop-ups is not merely nostalgic. I think there is something very interesting going on if we look at how programs for the web evolved between 1990s and 2020s. A major development is certainly a growth of complexity. In some cases, this is essential complexity. An application like Google Sheets is clearly doing more than what people envisioned in the 1990s. In other cases, the growing complexity is accidental. Web pages that simply display content nowadays load a lot of JavaScript for no apparent reason.
However, the way scripts and applications that run on the web are written has also changed:
-
Transpilation and bundling. The first notable change is that nowadays, most JavaScript is not written by humans, but generated by some kind of pre-processor. This may be a compiler that turns code in other languages, like F#, into JavaScript, a module bundler that inlines dependencies or a minifier that makes the resulting file smaller.
-
From windows to in-page elements. As I wrote above, web pages nowadays rarely use system windows and instead re-create similar experience inside the web page. Pop-up ads are one obvious example, but the same thing happens with standard dialog windows;
window.prompt,window.confirmandwindow.alerthave all been replaced by Bootstrap's modal and similar. -
Canvas and WebAssembly. Two recent technologies take both of the above trends even further. WebAssembly makes it possible to run binary code in the browser and so compilers for the web can increasingly avoid targeting JavaScript. Similarly, the
<canvas>element makes it possible to increasingly avoid using not just system windows, but also browser DOM elements. One example of this is Google Docs, which are switching to canvas-based rendering.
What do we gain?
Many of the above developments are motivated by performance. Bundlers and minifiers make resulting files smaller to download; WebAssembly makes it possible to produce efficient compiled code for high-performance calculations; even the Google Docs move to canvas-based rendering is motivated by performance.
A less frequently cited motivation for some of the above is that they hide more about a program from the system or the user. This is clearly the case for in-browser pop-ups, where the browser no longer sees what is going on in the page and cannot block it. It may also sometimes be the case for minification that makes the resulting JavaScript harder to copy. You can no longer just view the source and copy your favourite cursor follow effect! Although you can still view and re-format the source code, extracting any meaningful logic from it becomes hard.
Finally, compiling code in other languages to JavaScript is clearly motivated by programmers wanting to use their preferred (presumably better) programming languages. This is why most of my interactive web projects use F# under the cover! Interestingly, many of those compilers initially try to generate relatively clean JavaScript. The TypeScript web in 2012 said "TypeScript is a typed superset of JavaScript that compiles to plain JavaScript," but in 2021, the page only says that "TypeScript code converts to JavaScript which runs anywhere JavaScript runs." The F# to JavaScript compiler Fable still claims to produce "readable JavaScript," although actually reading the JavaScript output requires a fair bit of knowledge about internal representation of various constructs in F# and Fable.
What do we lose?
A more interesting question is what do we lose by the growing opacity of programs on the web. One interesting issue is accessibility, because assistive technologies like screen readers rely on being able to analyse the structure (DOM) of the web page. In the Google Docs announcement, the authors later added an "update" explaining that they will ensure such tools will continue to work, but this requires writing extra code that instructs the tools, rather than just relying on the fact that they can see the structure of the page.
More generally, the more the structure of the web page is hidden from the system, the more we
lose the ability to build tools that somehow leverage the structure. If you view the source of
a web page in modern developer tools (Figure 4), you can see the structure and manually modify
it (a useful trick to read some paywalled content!) You can also write a quick script to extract
some data from the page (I did this when dealing with some of our student records!)
Browser extensions like Greasemonkey rely on
this and there is also active research on how the openness of the web could enable new
user experience. For an impressive example, see Geoffrey Litt's Wildcard project.
None of this will be possible when all web rendering moves to <canvas>.
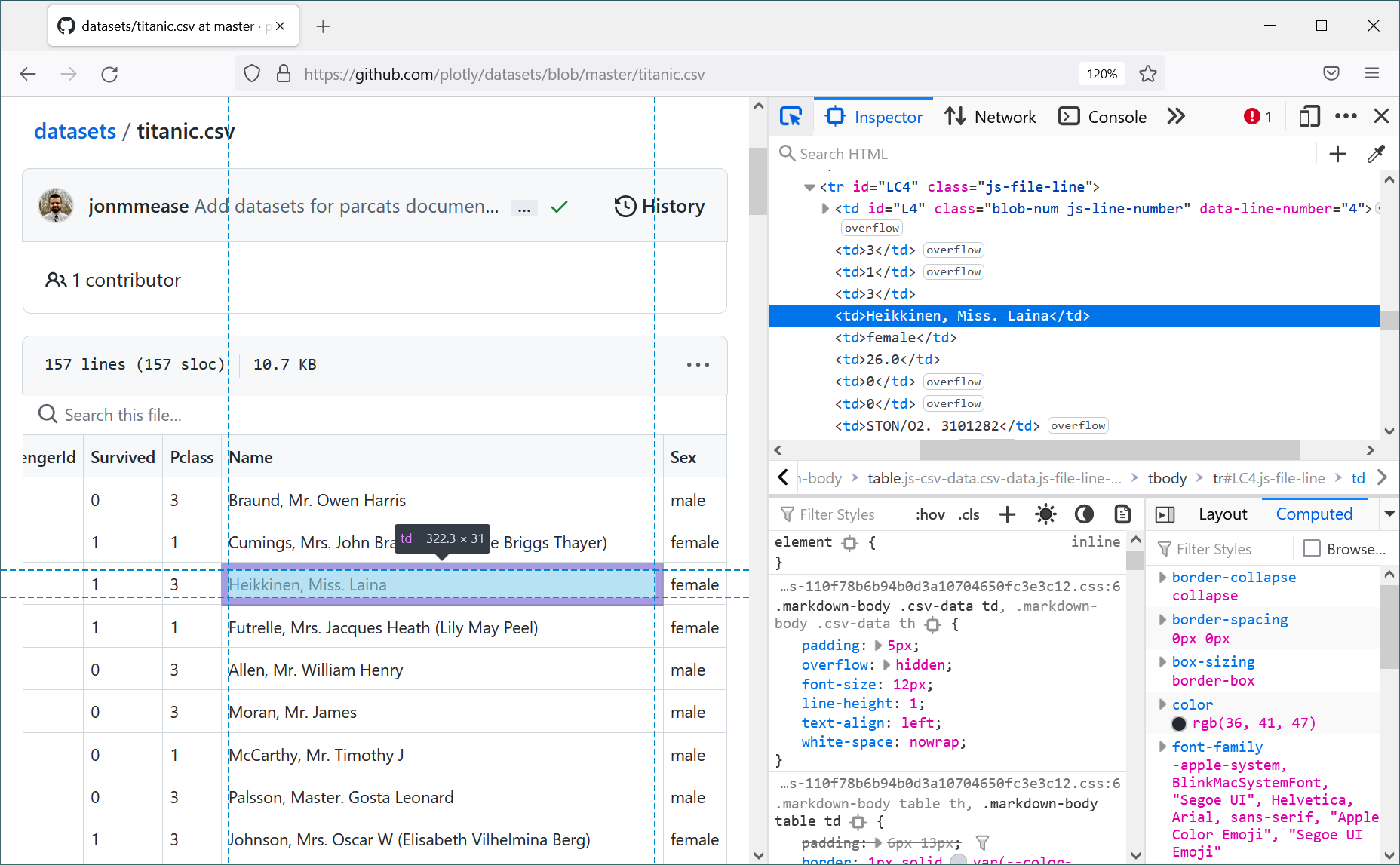
Figure 4. Viewing a HTML table in Firefox Developer Tools
Editor war for the 21st century
Before I share more general observations about software evolution, I want to briefly mention another interesting bit of recent software history, which is the competition between two text editors. I'm not talking about Emacs vs Vim, but about the competition between the Atom editor and Visual Studio Code. The two editors are based on a very similar technology. They are both based on the Electron framework, which makes it possible to write desktop applications in JavaScript, using web browser technologies for rendering.
Yet, there is one interesting difference, often attributed to (maybe not surprisingly if you read the above section) performance and extensibility. When you create an extension for the Atom editor, it gets a full access to the structure of the document. You can manually modify this (Figure 5) and you can create extensions that modify the structure in whatever way you want. This may go wrong (of course) but it also means that you can create quite powerful Atom-based tools. (I used this several years ago to create an interactive F# environment for data science.)
The side-effect of this design is that Atom extensions need to run in the same process as the main editor user interface, in order to be able to access the DOM. This is one of the reasons that make the Atom editor slower. (Reminding me of the "Eight megabytes and constantly swapping" joke about Emacs.) In Visual Studio Code, you can also manually look at the structure (as in Figure 5), but this cannot be done programmatically from an extension. Extensions are loaded as separate processes and they do not have full access to the document structure. This improves the performance, but it limits what extensions can do. They can only access the editor through the extension API. This includes all the expected extensibility points, such as adding support for new programming languages or creating new views, but it does not let you extend the editor in ways that the designers did not already think of. (At least, not without forking the editor itself.)
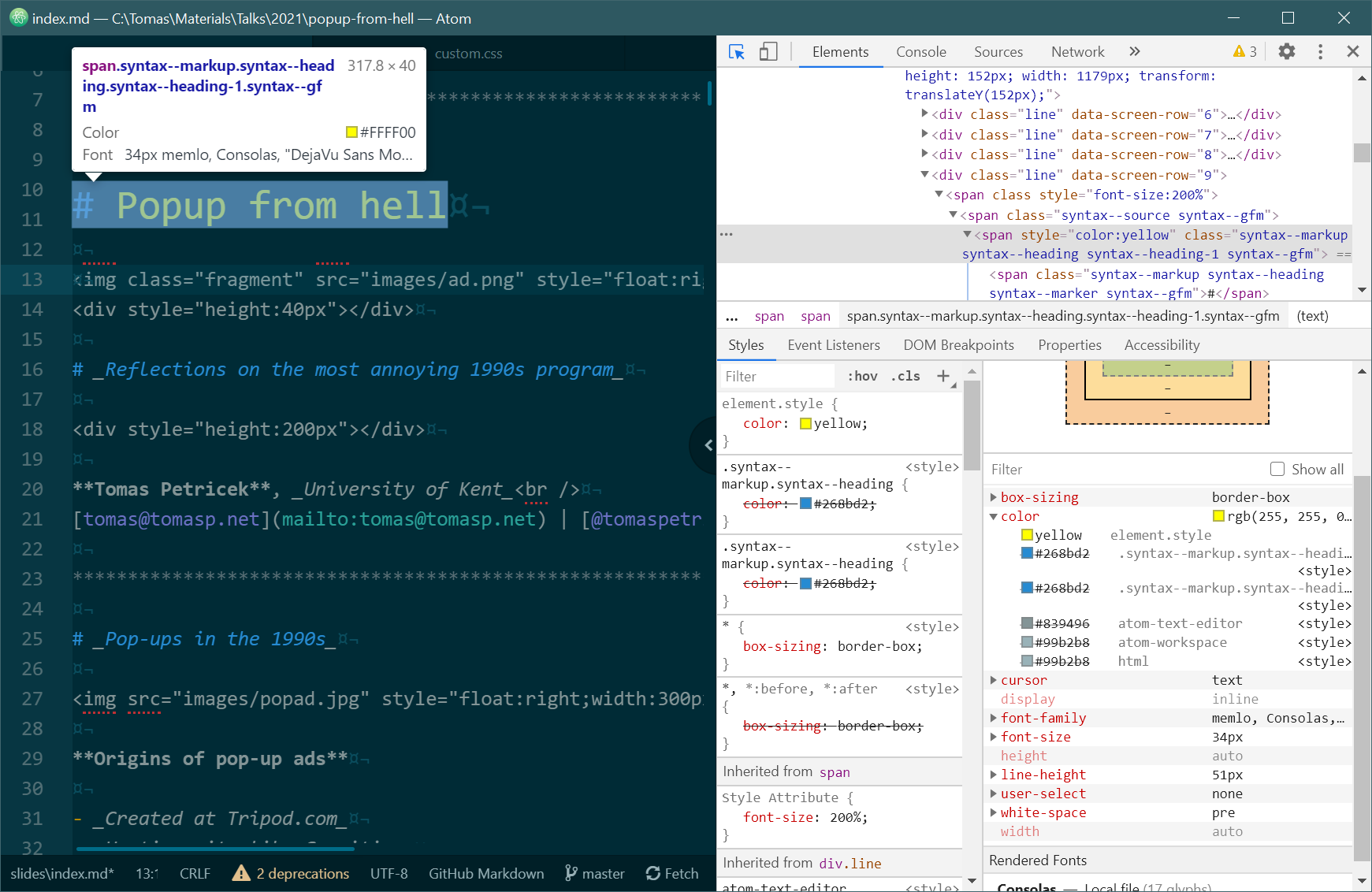
Figure 5. Manually editing the DOM in the Atom editor (and breaking things)
What is good for the User?
Many of the developments that make programs more opaque are presented as being good for the user. After all, who would not want a more efficient developer tooling or document processor? Yet, many of the developments that make programs opaque also take something from the users. In many of the discussions in the PROGRAMme project that I'm happy to be a part of, Liesbeth De Mol started using a distinction between a "user" and a "User" that I will follow here.
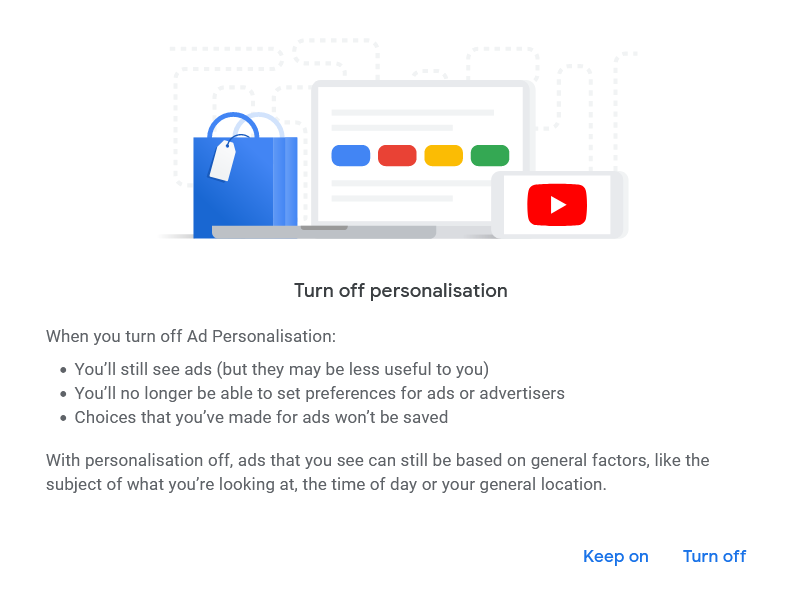
Figure 6. Disadvantages of disabling ad personalization
The User with upper-case U is an abstract persona constructed by corporations like Apple or Facebook that only needs what the companies provide. In contrast a lower-case user is a real human with interests not determined by the software they use. The transition from user to User follows a transition from hackers, who had not only their own interests, but were also often changing the software they used to suit their needs.
The growth of opacity is only a good thing for the User. It offers a more polished and efficient programs that perfectly address the needs of the User. In doing so, it leaves aside the needs of the lower-case u user and even more the needs of hackers who may actually want to modify the software they use to suit their needs. (In the case of pop-up blocking, the User defined by the software producers presumably wants to "engage with relevant advertisement opportunities" and see "more useful ads", Figure 6.)
Embedding of programs in a system
To make the idea of program opacity more precise, we can talk about the way in which a program is embedded in a system that hosts it. In case of the web, this is the relationship between the web application and a browser; in the editor war, it is the relationship between an extension and the editor. In some cases, the distinction is less exact. A Smalltalk program lives in the same image as the rest of the system, but we can still draw a line between the two.
The way a program utilizes the system in which it runs is a scale with two extreme ends that I'm going to call shallow and deep embedding (borrowing terms used in the functional programming language community for talking about domain-specific languages):
Figure 7. Smalltalk user interface
-
Shallow embedding. In this case, the program reuses as many features of the system as possible. Many aspects of the program are delegated to the system, meaning that the program may not have a full control over them (for example, the look of a user interface). Because of this, the system can see (to an extent) what a program works with and what is it trying to do. It can use this to implement assistive technologies or block undesirable program behaviour. (Stephen Kell's reflective Unix project can be seen as making Unix programs more shallowly embedded in the operating system.)
-
Deep embedding. Here, the program leverages only the minimum provided by the system and uses this to re-implement features (such as user interface elements) that are already provided by the system. One example is custom text rendering using
<canvas>when the browser already supports text rendering through HTML. Another example is on the boundary between Smalltalk runtime and the host operating system (rather than Smalltalk program running inside Smalltalk runtime), where the Smalltalk runtime does not leverage many of the operating system features.
Laws of program opacity evolution
In the case of the web, we can see an evolution from shallow embedding in the early days of the web to a deep embedding in the contemporary web technologies. In the case of the Atom vs. Visual Studio Code war, the latter forces extensions to use shallow embedding by restricting what the extensions can do (by offering only limited API) so that they have to rely on system features for most of what they do.
We can use this perspective to look at a number of other programs and systems. For example, the Apple AppStore attempts to prevent one particular kind of deep embedding through its terms and conditions when it forbids applications from using and downloading interpreted code (Apple does not go as far as it possibly could. In particular, it does let applications to control the look of their user interface, but you can easily imagine how that could become a requirement for "consistency reasons").
Is growth of opacity a law?
There are two questions with which I want to conclude the blog post. The first question is whether growth of opacity of programs is a kind of law of software evolution in the sense captured by Lehman. I only looked at a small number of cases to answer this, but some of the motivations for growing opacity seem very common. For example, compiling another language to JavaScript and attempts to improve performance are generally an attempt to do something better (bordering with the Not Invented Here syndrome). Yet, there are many ways in which the growth of opacity can be prevented:
-
Lack of resources. Simply not having resources to re-invent the wheel means that programmers will likely reuse more of the features offered by the system, rather than trying to recreate functionality on their own.
-
Community cohesion. Opacity of programs may not grow in small enough developer communities where everybody agrees that the system is well-designed. This is likely why there are so many compilers to JavaScript, but no compilers compiling other languages to Smalltalk (that I know of!)
-
Regulation. As already mentioned, Apple AppStore prevents certain forms of opacity through regulation in terms and conditions. This is another way of restricting program opacity.
When is opacity bad?
My second closing question is whether (the possibility of) the growth of opacity is a good or bad thing. It is certainly a characteristic of software that has a significant impact on the user (or the User). A more opaque system may be more efficient or may be able to achieve functionality that is otherwise impossible, but it is less open to modification and extensibility. I guess the question may be whether you as a user are more on the "side of system" or on the "side of the program".
-
On the side of the system. If I use a web browser to view a page that has some annoying pop-ups or a poorly sorted data table, I'm on the side of the system - I want to be able to use the system to control the web page, block pop-ups and extract data. In this case, shallow embedding allows me to do more.
-
On the side of the program. If I'm writing an application for iOS, I do not want to be told by Apple how to do things. If I want to download and interpret code (or create quirky user interface), I should be allowed to do that! In this case, deep embedding is the more desirable end of the spectrum.
As with my previous work looking at Commodore 64 BASIC, I think
there are interesting things to be learned from the history of the web. The growth of opacity
on the modern web has definitely allowed us to build more complex web applications, but it also
has its costs. Learnability and extensibility (if we all move to <canvas> and WASM) are
two such things. Now, you could argue that this is not really true, because many components that
are involved in modern web page construction are open-source (or even hosted on NPM) and are
in fact easier to reuse. I do not think this is the case, because it widens the gap between
the programmer and the (upper-case) User.
Published: Friday, 8 October 2021, 1:14 PM
Author: Tomas Petricek
Typos: Send me a pull request!
Tags: academic, research, web, philosophy, talks